カイ二乗検定はカイ二乗分布を利用する検定方法の総称である。カイはギリシャ文字のχである。χ2検定とも書く。アルファベットのエックス(x)に似ているが異なる文字なので注意。
母分散の検定、分布の適合度検定、分割表(クロス集計表)の独立性や一様性の検定などに利用される。統計モデルを構築した際に、データとモデルとの適合度の検定にも使われる。
<カイ二乗検定の例>
1.適合度検定
母集団においてk個の級 A1, …, Ak が互いに重複なく分類され、その確率をP( Ai ) = pi ( i = 1, …k )とする。∑ pi = 1 である。この確率分布pi = ( p1, …, pk ) が、母集団の分布πi= (π1, …, πk ) に適合するかを検定する。
標本サイズnとπi の積nπiが各級の期待度数である。観測度数をfiと書き表に示す。観測度数にO(Observed),期待度数にE(Expected)を記号として使う。
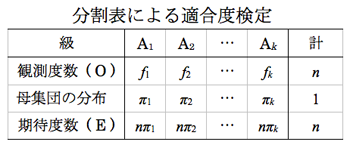
❶ 仮説の設定
帰無仮説 H0:pi = πi
対立仮説 H1:pi ≠ πi(H0の等号のうち少なくとも1つが不等号)
❷ 検定統計量:
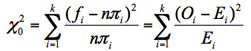
❸ 自由度:φ = k - c - 1
❹ 有意水準 α(通常はα=0.05に設定することが多い)
❺ P値が0.05より小さければ帰無仮説を棄却する。または棄却域 R: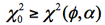
なら有意水準5%で帰無仮説を棄却する。
大標本のもとで期待度数nπiも十分に大きければ、帰無仮説H0が正しいとき、検定統計量は近似的に自由度φのカイ2乗分布に従う。
もしも観測値と期待値が等しければχo2=0となる。これは極端な場合で、実際にはいくらかの乖離があるだろう。カイ二乗値が小さい方が適合がよいということは直観的に理解できる。乖離が大きいほど検定統計量は大きくなるのだが、どの程度まで大きくなったら乖離していると判断するのか、つまり帰無仮説を棄却する(=有意である)大きさを設定しておく。通常は有意水準 α=5%で棄却域を設定する。設定した棄却域に検定統計量が含まれたら、あるいはP値がαより小さくなったら帰無仮説を棄却する。
なお自由度は、級の数 k - 1 だが、正規分布の適合度検定のように未知母数を含む分布の検定する場合、推定した未知母数の数(c)だけ、さらに自由度が減る。
下表は2011年11月の日経世論調査の年代分布(回答不明分を除いて再計算)と,国勢調査を基礎に作成された同月推計人口(総務省・確定値)から求めた年代分布である。世論調査の年代分布は、母集団の分布と同じだといえるか、有意水準5%で検定する。
| 年代 | 20 | 30 | 40 | 50 | 60 | 70~ | 計 |
|---|---|---|---|---|---|---|---|
| 世論調査 | 41 | 130 | 155 | 139 | 179 | 155 | 799人 |
| 5.1 | 16.3 | 19.4 | 17.4 | 22.4 | 19.4 | 100% | |
| 国勢調査 | 13 | 17 | 16 | 16 | 18 | 20 | 100% |
自由度:
d.f. = k - 1 = 6 - 1 = 5
検定統計量:
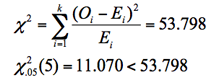
ところでこの例は検定するまでもなく、世論調査で20代は5%しかおらず、母集団の13%より著しく少ない。世論調査には若者の意見が十分に反映されていない。
2.独立性の検定
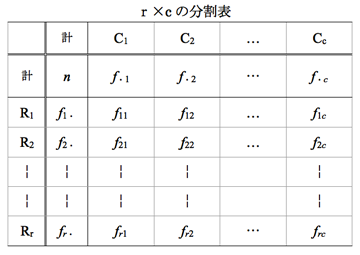
ある商品の所有率は男女で差があるかを検定したいとき、性別×所有(有無)の分割表(クロス集計表)を作る。所有率は性別に関係ない(独立である)という帰無仮説をたてるので独立性検定という。性別と所有は2×2の分割表であるが、一般に名義尺度の2変数は表のようなr 行× c列の分割表で表現される。
❶ 帰無仮説の設定
帰無仮説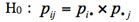 (すべての i, j にわたって)
(すべての i, j にわたって)
対立仮説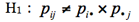
ここで、pijは各変数のカテゴリが(Ri, Cj)に属す確率である。pi・はRiに属す確率、p・jはCjに属す確率である。
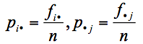
で計算される。
❷ 検定統計量
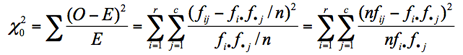
期待値を以下のように定義して書き換えると,式が見やすくなる。
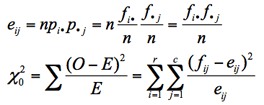
❸ 自由度:φ = ( r – 1 )( c – 1 )
❹ 有意水準 α(通常はα=0.05に設定することが多い)
❺ 棄却域R: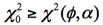
なら有意水準5%で帰無仮説を棄却する。あるいはP値<αなら帰無仮説を棄却する。
男女200人に、ある質問に対する諾否(はい・いいえ)を調査した。下表はクロス集計の結果である。母集団においても男女で意向率に差はない、といえるか。有意水準5%で検定する。
| Example-2 Quantum Manual |
Total | Yes | No | DK |
|---|---|---|---|---|
| Total | 200 100.0% |
61 30.5% |
113 56.5% |
26 13.0% |
| Female | 80 100.0% |
39 48.8% |
30 37.5% |
11 13.8% |
| Male | 120 100.0% |
22 18.3% |
83 69.2% |
15 12.5% |
自由度:d.f. = ( r -1 )( c - 1 ) =2
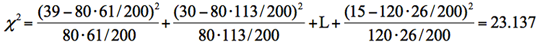
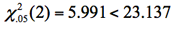
である。
大きなχ2値が観測され,有意水準5%で帰無仮説は棄却される。つまり男女で同じだとは言えない(性差がある)。
3.分割表の単分類検定
この検定は統計学のテキストには掲載されていない。クロス集計ソフトウエアであるQuantumにSingle Classification test (「単分類検定」あるいは「セル別検定」などの意味)として搭載されている。
マーケティング調査のクロス集計表は大部になることが多いので、集計表の解釈作業において、特徴のある場所を探すのに苦労する。そこで便利な方法が単分類検定である。このアイデアはすべてのセルを検定するもので、回答者全体の分布と有意差のあるセルに*印などをつける。
クロス表のあるセルに注目する。たとえば1行1列目のセルf11に注目する場合、以下のように「注目している一つのセル」と「それ以外」に二分し、回答者全体の行も同様に二分して2×2の分割表を、部分的に考える。
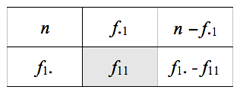
このセルf11は、たとえば性別が「男性」における,あるブランドに対する「認知」などであり、これが回答者「全体」の認知 f・1 に比べて大きな差異であるか否かを検定する。検定統計量は(0.1)式で与えられる。この検定をすべてのセルで実行するのである。
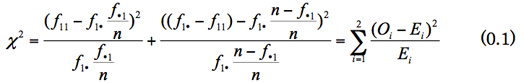
各セルの検定は、回答者全体の行を理論分布とみなせば、形式的には自由度1の適合度検定に相当する。また。回答者全体の比率を母比率π0とみなせば、形式的には(0.2)式の、母比率の検定と同値である。
検定の多重性を考慮していないという理論的問題はあるが、膨大なクロス集計表をめくりながら、注目すべきセルに*印がマークされる便利なツールとして利用することができる。
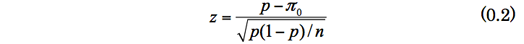
ここで、
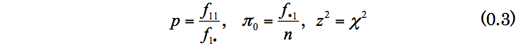
<カイ二乗分布>
母集団が正規分布N(μ,σ2)に従うとき,そこから無作為抽出したサイズnの標本を考える。別の表現をすると,n個の確率変数Xiが互いに独立に正規分布N(μ,σ2)に従うとき、標準化した確率変数の平方和Wは自由度nのχ2分布に従う[i]。
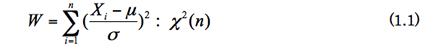
最初から標準正規母集団N(0,1)を考えれば,
と置き換えるのと同じではあるが,確率変数Ziの単なる平方和として以下のように表現することもある。

さて,実際には母数μやσは未知である。そこで標本平均![]() を使った統計量Yを定義する。Yは自由度n - 1のχ2分布に従う。
を使った統計量Yを定義する。Yは自由度n - 1のχ2分布に従う。
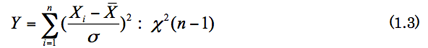
式 (1.3) は (1.1) と同じ形をしているが,母平均μを標本平均![]() に置き換えたことにより,自由度が1つ減ってn - 1になっている。これは標本平均の偏差の合計が,
に置き換えたことにより,自由度が1つ減ってn - 1になっている。これは標本平均の偏差の合計が,
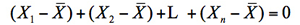
という制約を生じるためで,自由度が1つ少なくなる。母平均μの偏差の合計の場合はこのような関係は生じない。
式(1.3)は平方和
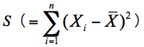
を使って,以下のように表現することもある[ii]。

同様にして,本質的に(1.4)と同じなのでしつこいのだが,標本分散s2(S/n)や,不偏分散V(S/n-1)を使って表現することもある。平方和による表現のほうが簡潔であろう。

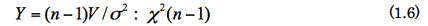
2.χ2分布のシミュレーションによる確認
確率密度関数を使ってχ2分布を描いた。左は自由度2,4,6の同時プロット。右は自由度2,4,10,30であるが、自由度が大きくなるにつれて分布が対称に漸近する様子が分かる。
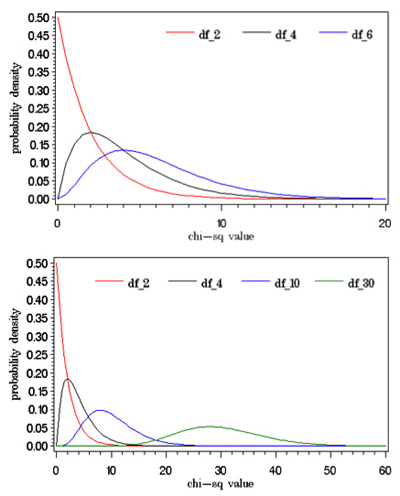
標準正規乱数Zを発生させて、標本サイズ5の平均値M、平方和W、偏差平方和Yを2万件作成し、その平均値と分散を求め、ヒストグラムを描いた。
シミュレーション結果をまとめると下表のようになる。
|
統計量 |
反復回数 |
平均 |
分散 |
|---|---|---|---|
|
M |
20,000 |
0.0 |
0.2 |
|
W |
20,000 |
5.0 |
9.9 |
|
Y |
20,000 |
4.0 |
8.0 |
標準正規母集団から無作為抽出したサイズnの標本平均値の平均(期待値)は0であり,分散は
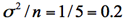
となっていることが確認できる。
χ2分布の期待値と分散は自由度の記号をfで表示すると[iii],以下のようになる。期待値が自由度になるというのは,平方和を分散で割るというχ2値の定義式,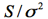 をみれば直感的に理解できるだろう(平方和を自由度で割ったものが分散であった)。χ2分布は平均値μや分散σ2とは無関係で,自由度のみで決まる。
をみれば直感的に理解できるだろう(平方和を自由度で割ったものが分散であった)。χ2分布は平均値μや分散σ2とは無関係で,自由度のみで決まる。

式(1.1)のようにWは自由度f = nのχ2分布をするので期待値は5であり,式(1.3)のようにYは自由度f = n -1のχ2分布をするので期待値が4になっていることが確認できる,分散も理論どおりほぼ2 f である。
[i] カイ二乗統計量の記号として,ここでは区別の必要からWとYを使った。区別の必要のない文脈ではそのままχ2の記号を使うことが多い。たとえば, 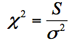 のように表記する。なおホーエルは「この名前はうまくつけてあるわけである」(入門数理統計学,250頁)と述べているが,χ2のどこがどうして「うまい」名前なのか日本人には分かりにくい。
のように表記する。なおホーエルは「この名前はうまくつけてあるわけである」(入門数理統計学,250頁)と述べているが,χ2のどこがどうして「うまい」名前なのか日本人には分かりにくい。
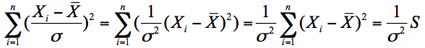
[iii] 自由度の記号は一文字で表記する場合はfのほかにm や,ギリシャ文字のφ,ν(ニューと読む)などが使われる。自由度の英語はdegree of freedomなので自由のf を使う習慣があるのだろう。f のギリシャ文字がφである。文脈からアルファベットを避けたい場合もありφを使うと思われる。νはnのギリシャ文字である。χ2分布の自由度が標本サイズnに関係するためであろう。標本サイズと自由度とを区別するため,自由度にギリシャ文字を使うという事情からνを使う。なおmを使う人はnとの区別のためだと思われるが,平均のmと紛らわしい。νはアルファベットのvに似ているので,これも紛らわしい。

