複数の説明変数を持つ回帰分析は、とくに重回帰分析という。「重」は説明変数が複数(multiple)であるという意味で使われている。応用的には単回帰分析よりも重回帰分析の利用場面が多い。しかし理論的な基礎はほとんど単回帰分析に含まれている(単回帰分析の項を参照)。
たとえば、重回帰分析が適用されるのは以下のような場面である。
- 総合満足度を目的変数とし、多数の個別満足度や個別重視度を説明変数として、どの側面が満足度向上に強く影響しているかを示す。
- 広告注目率を目的変数とし、広告の多数の属性を説明変数として、注目率を上げる要因を発見したい。
- 購入意向率や推奨意向率を目的変数とし、ブランド・イメージを説明変数として、どのようなイメージが購入に結びついているのかを明らかにしたい。
- 国政選挙の前に選挙予測調査を実施し、候補者への投票意向率を目的変数とし、候補者や選挙区の多数の属性を説明変数として、得票率を予測する。
- 営業利益率を目的変数とし、そのほかの財務指標を説明変数として、営業利益率に影響の強い指標を見つける。
- 倒産企業と優良企業のデータを準備し、倒産を目的変数とし、財務指標を説明変数として倒産危険度の予測モデルを構成する。
<ブランド・イメージの重回帰分析>
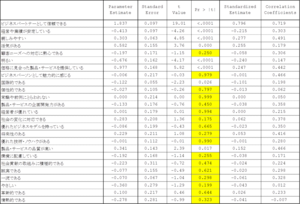
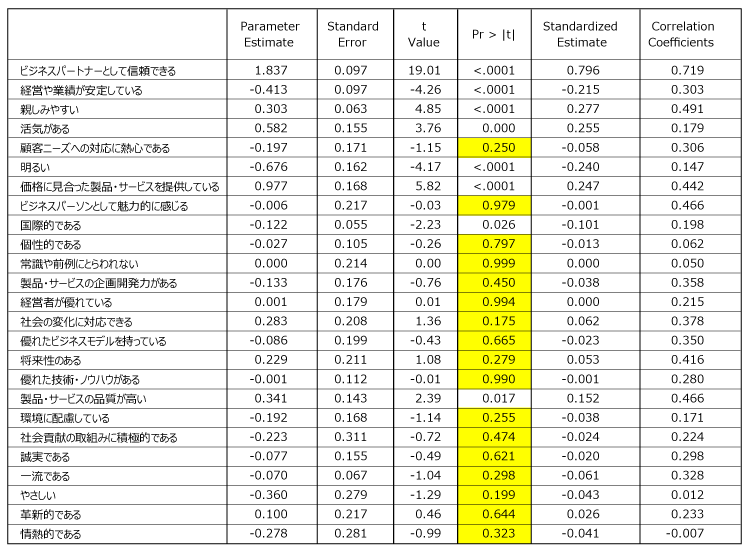
日経リサーチの「ブランド戦略サーベイ」のデータの一部(332社)を使って、目的変数を購入意向率とし、説明変数をブランドイメージ(25変数)として重回帰分析を適用した例を示す。自由度調整済決定係数は0.77で、まずますの高さであった。
偏回帰係数(Parameter Estimate)、標準化回帰係数(Standardized Estimate)、相関係数(Correlation Coefficients)、および検定結果を下表に並べた。この結果をみると以下のことが分かる。
- 有意(P < 0.05)でない説明変数がある。有意な説明変数は7個しかない。
- 有意でない説明変数は相関係数(Correlation Coefficients)が低いとは限らない。有意になった説明変数よりも高い相関係数の変数さえある。
- 標準化回帰係数と相関係数の値は異なる。大小関係も変わる。符号さえ違う変数がある。
- 標準化回帰係数の二乗和は決定係数に一致しない。つまり全体の決定係数を、個々の説明変数の寄与率に分解することは数学的にできない。
このような結果になる理由は、説明変数が互い相関を持つためである。この状態を共線性(collinearity)あるいは多重共線性(multicollinearity)という[i]。
有意でない変数が「重要でない」という意味ではない。偏回帰係数の数理的性質による結果である。このような結果をみても、重回帰分析によって目的変数に影響力の強い要因を探す、ということは単純ではないことが分かる。単純な比較が目的なら、むしろ相関係数の大きさを比べた方がよい。信頼が重要で、情熱は無関係――と相関係数は納得の結果であろう。
偏回帰係数や偏相関係数の「偏」は英語のpartialの訳語である。「他の変数の影響を除いたうえでの当該変数の影響部分」という意味で使われている。偏回帰係数の場合は、「他の説明変数の値が一定のもとで、その説明変数が目的変数に与える影響」である。これを踏まえて係数を解釈する。
多重共線性の回避策として変数選択を利用することも考えられる。有効な変数の組を探す手法として各種の変数選択法が提案されている。ただし選択されなかった変数が無意味ということではなく、相関関係を考慮した結果に過ぎない。調査は重回帰分析モデルのために設計されているわけではなく、測定項目は調査目的に沿って用意されたものである。
もう一つの対策として変数合成が考えられる。主成分分析であれば完全な直交変数を作ることができるので、標準化回帰係数は相関係数のように解釈できる。成分の解釈が難しければ因子分析も有効である。「のれん」「活性力」「大衆性」「先鋭性」の4因子を説明変数にすることで、抽象度は高まるが見通しは簡潔になる(4因子については因子分析の項を参照)。
<回帰モデルの評価>
重回帰分析の結果を得たら、そのまま鵜呑みにして直ちに結果の解釈をするのではなく、重回帰モデルが適切か否かを、まず評価する。統計ソフトウエアには以下のような評価指標も出力される。
- モデル全体が有効か。分散分析(F検定)が有意でなければならない。
- 個々の偏回帰係数は有効か。t検定が有意でなければならないが、有意であっても予測力が低いこともある。自由度(≒データの件数)が大きければ有意になりやすい。
- 予測力は十分か。自由度調整済決定係数の大きさは、目的を満たしているか。決定係数と自由度調整済決定係数に大きな差がある場合は、モデルに問題がある可能性が高い。決定係数は説明変数を増やせば、増やすほど100%に近づくが、将来予測は不安定になる。
- 重回帰分析の場合は自由度で調整した決定係数で判断する。決定係数は平方和の比であったが、自由度調整済決定係数は平均平方の比である。調整とは平方和を自由度で割った(自由度1個あたりの平方和の比に調整した)という意味である。
- 予測の信頼区間は実用的な範囲であるか。決定係数が大きくても予測誤差が大きくては、実用的に無意味な場合がある。「明日は天気から雨の範囲である」という予測誤差では実用的に無意味である。
- 回帰診断をする。モデルの仮定を満たしているか。特に残差分析による正規性・無作為性・外れ値のチェックが重回帰モデルでは重要である。多変量外れ値は主成分分析も有効である。
- 有意でない説明変数が含まれているとモデルが不安定になり、評価指標のどこかに出てくる。AICによる比較も有効。これは変数選択の問題に関連する。
<実際的な諸問題>
重回帰分析は単回帰分析の拡張である。基本的な性質は単回帰分析に含まれているが、重回帰分析は複数の説明変数があるため、以下のような特有の注意点がある。
- 回帰係数の解釈が、単回帰分析のように単純ではない。標準化回帰係数においても、単回帰係数は相関係数と同値だが、重回帰分析では相関係数のような解釈ができない。相関係数とは値が異なり、符号さえ相関係数と逆転することがある。
- 多くの説明変数の中から、有効な変数をどのように選ぶかという変数選択、モデル選択の問題が生じる。
<偏回帰係数の解釈>
説明変数が2個の場合の相関係数行列と偏回帰係数を下表に示す。
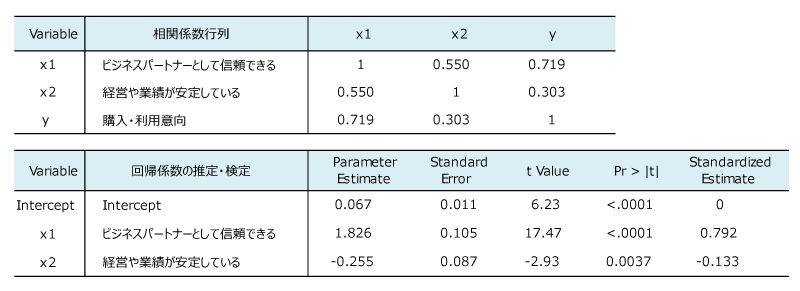
分析結果によれば。重回帰分析モデルは以下の通りである。
y = 0.067 + 1.826 x1 -0.255 x2
「経営や業績が安定している」の符号がマイナスなので、安定感が無い方が購入増となる、と解釈してはいけない。相関係数は0.303であり、安定イメージも購入意向にプラスの影響を与える。
「信頼できる」が同じ水準の企業を集めたとしたら、安定イメージはマイナスになると解釈するのである。つまり同レベルの「信頼」ある企業であれば、安定した老舗でなくとも、新進の企業で安さ・早さを訴求しているような躍動的なイメージが購入意向に結びつくのかも知れない、というような解釈に進んでいく。
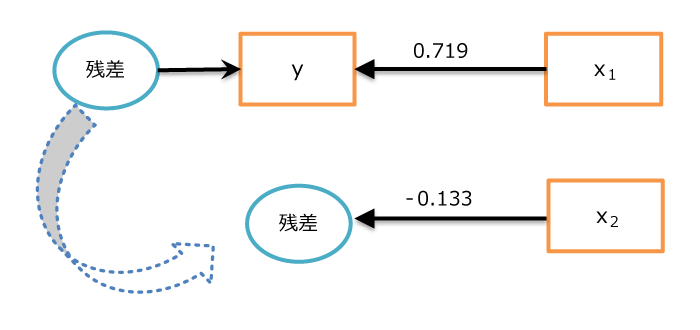
他の変数が一定のもとでの当該変数の影響、という説明を別の観点で示す。すなわち「安定」の偏回帰係数は、「信頼」で「購入意向」を説明した残差を、「安定」で回帰分析したときの回帰係数である。実際に、残差を目的変数、「安定」を説明変数とした単回帰分析の結果を確認する(下表)。

標準化偏回帰係数が「-0.133」となっている。この値は、2変数を説明変数とした重回帰分析における、「安定」の標準化偏回帰係数と同値になっている。「信頼」で説明した残り物(残差)の中には、信頼イメージによる効果はもう含まれていない。その残差をさらに「安定」で説明するとしたら、どのような構造が残っているか、という分析をしていることになる。「信頼」と「安定」は類似の方向性を持っている(相関係数は0.55)ので、「信頼」で説明した残差には、その情報はない。「安定」は「信頼」では説明しきれなかった残りを説明するように作用する。以上の説明の図解は以下のようになる。
極端な例として、相関係数1.0であるような2変数だったら、一方だけあれば十分であり、他方は用無しである。実際には推定できないが、相関係数0.9程度の高さの相関であれば計算できる場合もある。しかし推定値は極端な値になり、大きな標準誤差を示して、有意ではない結果となるだろう。これが多重共線性問題である。
<変数合成>
説明変数が多数の場合は、変数合成をする手段もある。ブランド・イメージの25変数は、重回帰分析にとっては「多い」。
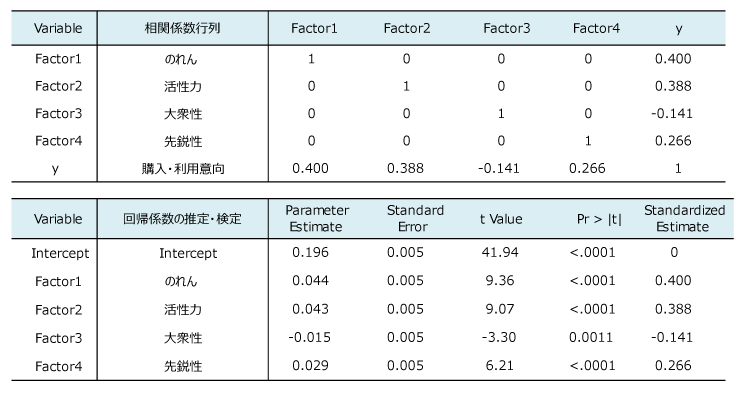
変数合成の手段として主成分分析がある。4成分を採用して重回帰分析を適用した。自由度調整済決定係数は0.394であった。説明変数25個の決定係数(0.77)より低下した。これは4変数のみであることと、また4成分は25変数の63%(第4固有値までの累積割合)に情報を縮約しているからである[2]。
相関係数行列をみて分かるように、4成分は無相関である。これを直交ともいう。説明変数が無相関の場合、標準化偏回帰係数は単相関係数と同値であり、その平方和は決定係数(自由度で調整しない)に一致する。すなわち、決定係数(0.401)を4成分の寄与率に正確に分解できる。
( 0.400 )2 + ( 0.388 )2 + ( -0.141 )2 + ( 0.266 )2 = 0.401
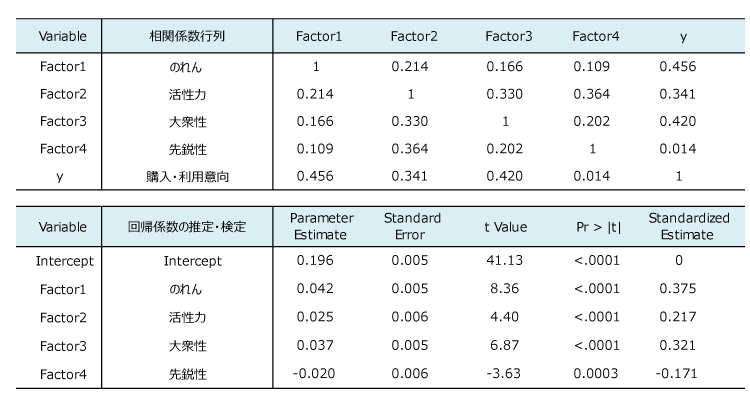
因子分析の利用もできる。やはり4因子で重回帰分析を適用した。自由度調整済決定係数は0.370であった。因子分析で因子得点を求めた場合、一般に因子間は無相関にならない。さらにこの場合は斜交回転解なので、その影響も出る。そのため、標準化偏回帰係数の平方和は、決定係数( 0.378 )と正確には一致しない。
( 0.375 )2 + ( 0.217 )2 + ( 0.321 )2 + ( -0.171 )2 = 0.320 ≠ 0.378
<変数選択>
有用な変数だけを選択するために、以下のような手法がある。「有用」とはあくまでも「統計的な基準に照らした」有用性という意味である。
- 総当法
- 増加法
- 減少法
- 増減法(Stepwise法)
総当法の計算時間を気にすることはなくなった現在では、膨大な組み合わせからベストな選択を探すことができる。総当法を除いた選択法の場合、いずれも何らかの基準を設定しているのだが、代表的な選択法である増加法、減少法、増減法の結果を比較してみる。手法によって選択結果が異なるが、決定係数の観点からは25変数モデルに劣らない高い説明力である。
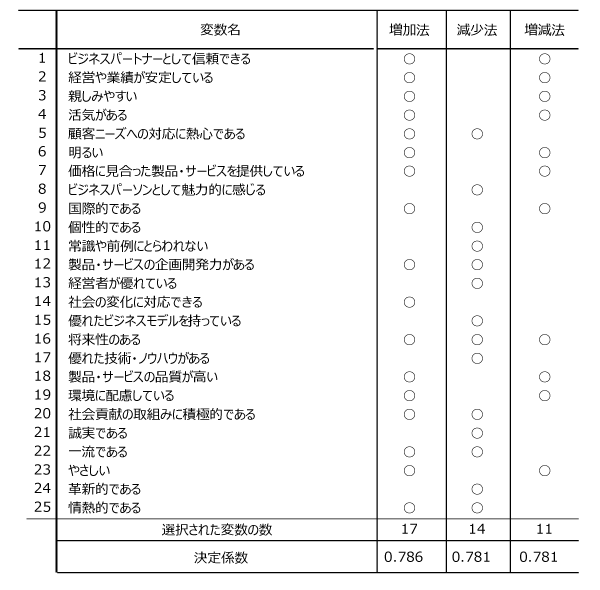
最後は目的に照らして分析者が決める。増減法(stepwise)が比較的、良好な結果を導くといわれているが、上表の11変数モデルでも2個の説明変数(18と19)は有意ではなく、除外して9変数モデルにしても決定係数は0.78(自由度調整済も0.77)と良好である。
<モデル・ビルディング>
よい予測モデルを構築すること(モデル・ビルディング)はデータサイエンティストの力量を示すものでもある。機械学習や人工知能で「自動的に」最良のモデルを探す技術も進歩しているが、それも重回帰分析を基礎にしながら、限界を突破するために、非線形モデルを考え、隠れ層や初期値の設定方法を工夫し、モデルの安定性を確保するために大規模なシミュレーションを組み込む等の積み重ねであるから、重回帰分析の理解はビッグデータ時代でも有益な基礎である。
モデル構築の簡単な例として、高次の多項式やダミー変数の利用などがある。Anscombeのデータ(相関係数の項も参照)を例にして説明する。
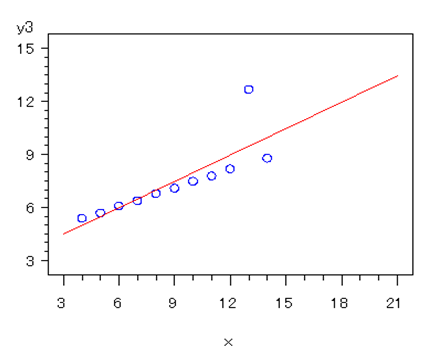
以下のようなデータの場合、二次の項(説明変数の2乗)を追加すると説明力が向上する。このデータでは決定係数1になって完全に説明してしまう。選挙予測データなどは三次曲線になることが知られている。ただ、四次以上の高次の項を追加しても複雑になるだけである。モデルは簡素な方が強固になる。

以下のようなデータの場合、ダミー変数を追加すると説明力が向上する。これも完全に説明してしまう。ただし、外れ値は除去すべき対処が妥当な場合もあるし、データを層別すべき場合もあるので、予備解析や回帰診断によって、データの内部構造に対して、慎重な探索と判断が必要である。無暗にダミー変数を追加して決定係数を上げても、予測モデルとしては将来の予測力を不安定にすることがある。つまり手元のデータはよく説明できても、将来には適合しないモデルになることもある。
<重回帰モデルの幾何学的な説明>
単回帰分析の幾何学的説明は「平面上の散布図に直線を当てはめる」ということであった。では重回帰分析の幾何学的説明はどうなるかというと、3次元区間に平面を当てはめることになる(下図)。これは説明変数が2個の場合である。3個の場合は、4次元空間に3次元空間を当てはめることであるが、もはや図示できないので想像になる。一般に重回帰分析は多次元空間に超平面を当てはめるわけだが、私たちには幾何学的な認知はできない。しかし数理的には計算可能である。

[i] 多重共線性のことを「マルチコ」という場合がある。「マルチコリニアリティー」を略してマルチコである。業界ではよく聞くので、知っていないとコミュニケーションがうまくいかないが、あまり使わない方がよい。対応分析(コレスポンデンス分析)をコレポンという場合もあり、これも同様である。
[2] ここでの主成分分析は「変数の分散を1に基準化した相関行列を主成分分析したもので、その結果をバリマックス回転した」。回転した場合は厳密には主成分分析とはいえない。因子分析の主成分解という。主成分分析と因子分析の類似と相違については、やや高度な話題なのでここでは踏み込まない。

