母集団のすべてを調査する全数調査(悉皆調査)に対して、母集団の一部のみを調査する標本調査では、標本を選ぶ方法が必要である。無作為抽出と有意抽出の二種類があり、さらにそれぞれ具体的な抽出方法が考案されている。有意抽出は意図的(有意)に標本を選ぶが、無作為抽出は作為的な手順を使わない点が異なる。
無作為であるということの、理論的な本質は「確率的に」選ぶという手続きにある。そのため無作為抽出は確率抽出ともいわれている。有意抽出は非確率抽出である。
無作為抽出(確率抽出)とは、母集団のすべての要素に抽出確率を与えて、その確率に従って標本抽出することである。すべての要素の確率が計算可能であること、また確率は0より大きく1以下の範囲であること(0<確率≦1)。この確率の与え方、抽出手順の違いによって無作為抽出はさらに様々な名称(系統抽出、多段抽出、層化抽出など)で区別されている。
以下の4例は、いずれも無作為抽出ではない。
例1 「全国の一般消費者から千人を調査するために、母集団の性・年代区分(直近の国勢調査結果)の分布と同じになるように、千人を性別×年代区分の各セルに割当てたうえで、各セルにおいて調査に協力してくれた人から順番に、計画人数に達するまで調査した」
例2 「商品Aは郊外に住む二世代家族に向けて開発するので、その条件に合致する世帯を探し、快く応諾してくれた家族に商品ニーズを探る調査を依頼した」
例3 「あるサービスの利用者300人に商品評価を調査したいので、日経リサーチ社内で利用者を見つけ、その友人・知人で同じサービス利用者を紹介してもらって調査を実施。その回答者にも友人・知人の該当者を紹介してもらう、という手順で次々に回答者を獲得した」
例4 「明日のテレビの特別番組で東京都民の都知事に対する支持率(世論)を報道するために、放送前日の通勤時間帯から帰宅時間帯まで、スタッフを総動員し、カメラとマイクを持って新橋駅前・新宿駅前・渋谷駅前で、道行く人々にマイクを向け、拒否されたら次の人を捕まえて質問し、最終的には千人以上もの多数の回答を得た」
例1は割当法、例2は典型法、例3は機縁法(雪達磨法)と呼ばれる、いずれも有意抽出である。例4に名前は無いが、俗に「駅前調査」などと称される方法である。
標本サイズが大きくても、無作為抽出をしたことにはならない。調査協力を拒否した人を断念して、親切に協力してくれた人だけを選んでは無作為抽出にならない。確率的手順で抽出されたら、別の人に交代してはいけない。実践的にはここが標本調査を困難にしているところである。質の良い標本調査はしたいけれど、拒否している人に無理強いはできない。
例1~例4は、それぞれの背景にある実施目的に合致した方法である。母集団を定義し、標本から母集団を科学的に推測する、という目的とは異なるだけである。
<なぜ無作為抽出をするのか>
標本から母集団の特性を推測するためである。統計的推測にあたって、母集団の真の値と比較して、標本調査で得た値が、どの程度の誤差(精度)であるかを計算できるようにし、科学的に判断するためである。この手順は標本抽出理論として確立されているが、そのためには標本が無作為抽出されていなければ、理論が適用できない。
たとえば、標本調査の結果で、ある商品の満足度が50%であったという結果を得ることができる。しかし母集団においても50%であるとはいえない。これは母集団の要素をすべて調査していないことによる標本誤差があるからである。しかし標本誤差の大きさを推測することができる。
統計的推測の表現は推定と検定である。推定は「95%の信頼区間」のような表明で、誤差の幅を表現するのである。「45%~55%の信頼区間である」というように。
検定には様々な方法があるが、Aの満足度50%とBの満足度55%であったとき、母集団においても差があるといえるのか、という仮説を検定する。あるいは男女別に利用意向率をクロス集計して、母集団においても利用意向率に男女差があるのかを検定する。
精度(誤差)から逆算すると、その程度の誤差より小さい誤差となるように調査を実施するためには、何人に調査すればよいのか、という論理で標本の大きさを決めることもできる。
400人から500人の調査がもっとも小規模であるが、これは±5%程度の誤差を見込んでいるのである。100人しか調査しないと±10%程度の誤差になるので、調査結果の解釈では「何割の人が~」というように百分率の1位は誤差として議論しない。数十人となると、もはや割合の計算はしないほうがよい。例1~例4の標本からは、このような評価・計算ができない。
<無作為抽出の主な種類>
・単純無作為
無作為抽出の理論的基礎で、母集団のすべての要素を等確率で抽出する。
・系統抽出
無作為抽出を簡単に実現する手順で、等間隔抽出ともいう。最初の要素だけを乱数などで抽出したあと、等間隔で順番に(系統的に)抽出する。
・層化抽出
母集団に関する知識を使って、たとえば全国を県別に層化したうえで抽出する。適切な層化をすると、単純無作為抽出よりも推定精度が高まるので、ほとんどの大規模な標本調査では可能な限り層化している。
・多段抽出
二段階、あるいは三段階に分けて抽出する。まず全国から調査地点を抽出し、次の段階では地点内の個人を抽出する。これは二段抽出である。多段抽出は単純無作為抽出よりも推定精度が悪化する。
・確率比例抽出
たとえば地点を抽出する際、あるいは企業を抽出する際、地点人口は異なるし、企業従業員数も異なる。そのような場合、人口や従業員数の大きさの比例した確率で抽出する。
・集落抽出
集落をクラスターともいう。まず集落を抽出し、次に集落内の要素をすべて抽出する。二段抽出との相違は、二段目は抽出しないで全数調査する点である。
<無作為抽出と単純無作為抽出>
研究者によっては、以下のように用語を使い分けている場合がある。
無作為抽出 ・・・・復元抽出
単純無作為抽出 ・・非復元抽出
一方で、無作為抽出を確率的な抽出方法の総称のように使っている場合もある。そこで紛れが生じないようにするために、以下のように書く場合もある。
復元単純無作為抽出
非復元単純無作為抽出
<単純無作為抽出の手順>
単純無作為抽出を実施するためには乱数を使う。乱数にも何種類かあるが、コンピュータを利用する場合は擬似乱数が簡単である。
復元単純無作為抽出を実施するには区間(1,N )の整数一様乱数をn個発生させ、該当する要素を抽出すればよい。
非復元単純無作為抽出を実施するには、いくつかの方法が提案されている。母集団サイズが小さければ、N個の一様乱数を発生させて、母集団の要素を昇順か降順に並び替えて、最初のn個を標本とする方法が簡単である。母集団を並び替えることができない場合は、区間(1,N )の整数一様乱数を発生させながらn個に達するまで抽出する方法がある。ただし同じ乱数が出た場合は抽出しない。
単純無作為抽出は母集団の要素が電子ファイルで存在しない場合、適用困難な場合が多い。電話調査におけるRDDのように、電話番号空間が母集団の場合には容易である。
<単純無作為抽出の小さな例>
単純無作為抽出は理論的にも基礎であるが、直感的にも理解の基本となる。手元の標本がどのような性質を持っているのかを実感できるようになることが重要である。また、無作為抽出を採用しないで調査を企画する場合にも、調査データの性質を洞察する力を養う素養となる。性別・年代別の分布を国勢調査(母集団)合わせて標本を回収すれば、あるいは分布に合わせるように重みを与えて集計すれば、代表性を備えるので統計的推測が可能となる、というような誤解もなくなる。
大きさnの「すべての可能な標本」を等確率で抽出する方法を単純無作為抽出という。母集団に含まれる個々の要素の抽出確率も等しい。大きさNの母集団から大きさnの標本X1, …, Xnを非復元抽出で単純無作為抽出する場合の「すべての可能な標本」の数は,
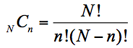
で示した公式の「組み合わせの数」だけある。1億人の有権者から千人の標本を抽出することを考えると、ほぼ無数の標本が可能であり、1回の世論調査というのは、その中のただ1つの標本を得た、ということなのだと理解・実感できることが重要である。
N=1億人、n=千人では大きすぎて複雑になり理解を妨げるので、N=5,n=3の場合の小さな数値例で確認してみよう。原理的には同じことである。母集団を構成する要素を{ 1, 2, 3, 4, 5 }とすると、母平均μと母分散σ2は、
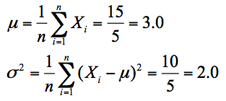
この母集団から大きさ3の標本を非復元単純無作為抽出する場合、すべての可能な標本数は表に示したように10標本である.各標本が抽出される確率はいずれも1/10で等しい。母集団の各要素{ 1, 2, 3, 4, 5 }が標本に含まれる確率(包含確率という)もそれぞれ6/10(=3/5)で等しい。見方を変えると、どの要素の抽出確率も1/N(1/5)であり、標本サイズ3の標本に含まれる確率は3×(1/5)=3/5である。
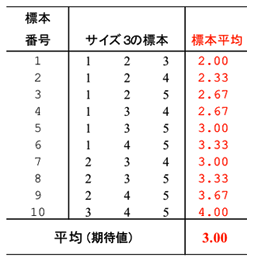
母平均は3だが、標本平均で3を得るのは標本番号5と7だけであり、運よくこれを抽出するとは限らない。しかし、理論的に重要な性質として「標本平均の平均は3」となっていることが確認できる。無作為抽出をすると、標本平均の分布の性質が分かっているので、ここから精度を評価できる。これが統計学の教科書の最初に出てくる確率変数と確率分布の話である。
復元単純無作為抽出では、同じ要素も抽出される。出現する標本数はNのn乗だけある。N = 5,n = 3の場合の標本数は125となる。
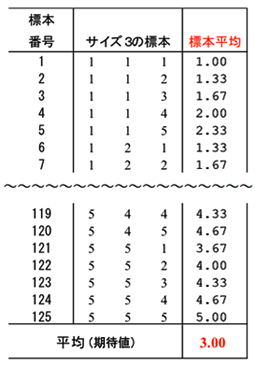
復元単純無作為抽出の場合も「標本平均の平均」は母平均に一致していることが確認できる。
非復元単純無作為抽出と復元単純無作為抽出の標本平均の分布をヒストグラムに描いてみた。母平均を中心に対称に分布していることが観察できる。これは小さなデータであるが、すでに標本平均が正規分布するという予感を示している。


