ランダムフォレスト(random forests)は機械学習のアルゴリズムのひとつで、決定木による複数の弱学習器を統合させて汎化能力を向上させる、アンサンブル学習アルゴリズムである[1]。おもに分類(判別)・回帰(予測)の用途で使用され、以下の特徴がある。
- 学習方法は単純だが、一般的な決定木より性能のよい識別・予測ができる
- CHAIDとは異なる接近法で多クラス問題に拡張した
- 非線形関係も分析できることで、線形回帰・判別の限界を超える余地がある
- 森の大きさを拡大しても過学習が生じない(数百以下で精度が収束する)
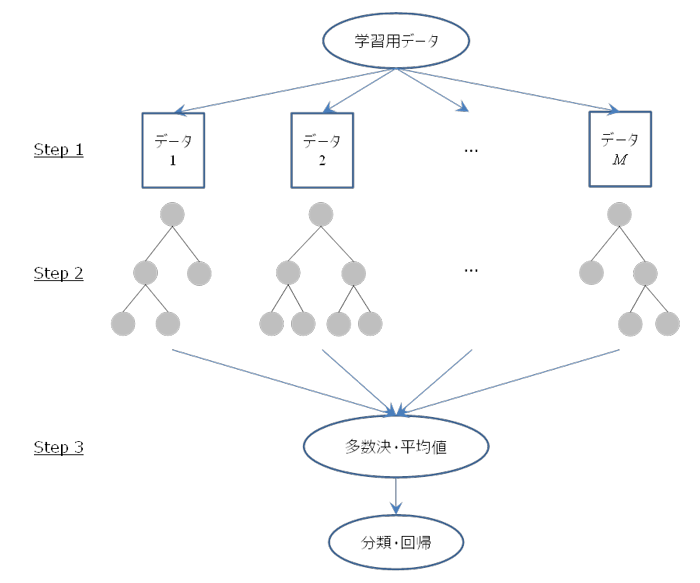
具体的な学習方法は図1のように、クロス・ヴァリデーション(相互検証法・交差妥当化)をベースとするシミュレーション法として実施する。
Step1では、全体の2/3の学習用データからM個のブーストラップ標本を抽出する。Mが森の大きさ[2]である。1個のブートストラップ標本の大きさ n は、原則として学習用データ(全体の2/3)の大きさである。
1/3は評価・検証用データとして残す。これを学習鞄の外に取りおくという意味からOOB(Out of Bag)と呼ぶ。
Step2では、各ブートストラップ標本において、全変数のうちから d 個の説明変数をランダムに選択したうえで、決定木を成長させる。最適な d の推奨値はあるが、分析者が問題を考慮した d を与えることもできる。
Step3では得られた各決定木の結果を統合する。分類・判別問題では多数決で、回帰・予測問題では平均値で統合し、学習器を構築する。
OOBに対して、学習用データで構築したモデルを当てはめ推定誤差を求める。分類・判別問題では誤判別率、回帰・予測では平均二乗誤差を指標とする。この推定誤差から説明変数の重要度を求めることができる。
<使用例:Fisherのiris(あやめ)のデータ>
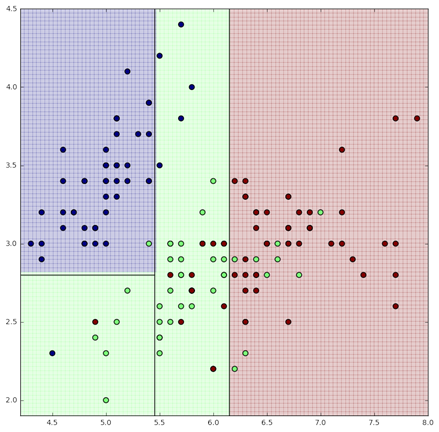
判別分析の例として有名な「irisのデータ」を用いて、ランダムフォレストと一般的な決定木との予測精度の比較をした。
「花びらの長さ」と「花びらの幅」の2変数からあやめの3種類(setosa、versicolaor、virginica)を分類する[3]。図2の分類結果では、決定木の正答率が83%に対し、ランダムフォレストの正答率は98%と高い。

マーケティングでは、特にWebサイト上での行動履歴や、登録された個人の属性情報を用いるデジタルマーケティングの分野で、ランダムフォレストが使用されることが多い。
- 優良顧客になりそうか
- 今後、離反しそうか
- 商品を購入しやすいか
などさまざまな場面で、ユーザを分類して表示するメッセージの選別や、割引オファーの変更などが可能となる。このような分類・判別をするニーズに対してランダムフォレストは有用である。
Random forests, Machine Learning, Vol.45, No.1, pp.5-32, 2001.

