統計的推測には推定と検定があり、検定(test)はその一方である。目的に応じて多くの検定法が開発されていて、検定とはそれらの総称である。「統計的検定」「有意性検定」「仮説検定」「帰無仮説検定」などの呼び方もある。単に「検定」と言わずに区別すべき理由が存在するのだが、それは後述する。調査データにおいて利用される検定法としては、以下のような種類がある。
●t分布による検定(t検定とも呼ばれる)
●F分布による検定(F検定とも呼ばれる)
●χ2分布による検定(χ2検定とも呼ばれる)
●正規分布による検定(正規検定とは呼ばれない*)
*正規性の検定と、正規分布を使う検定とは違うので注意。正規分布をz分布ということがあり、それにならってz検定という場合もあるが、これもあまり一般的な呼称ではない
<検定を利用する場面例>
1.新内閣発足でマスコミ各社が緊急世論調査を一斉に実施した。A紙の内閣支持率は60%(回答者数=1088人)、B紙は66%(回答者数=1018人)であった。A紙とB紙は同じ母集団からの無作為抽出標本といえるだろうか。
2.C紙の内閣支持率は64%であった(回答者数=1057人)。C紙はA紙より内閣支持率がいつも高い傾向にあるように思える。今回の調査結果からは母集団においてもC紙はA紙より「高い」と判断できるか。
3.D紙の世論調査で内閣支持率が先月の45%(回答者数=886人)から、今月は43%(回答者数=948人)へと低下したが、母集団においても「低下した」と判断できるか。
4.内閣が有権者の過半の支持を失ったのか否かは微妙な時であった。A紙が実施した世論調査で内閣支持率は48%(回答者数=2115人)であった。母集団においても有権者の過半の支持(50%)を失ったと判断できるか。
5.2011年11月の日経世論調査の年代分布(回答不明分を除いて再計算)と,国勢調査を基礎に作成された同月推計人口(総務省・確定値)から求めた年代分布がある。世論調査の年代分布は母集団(国勢調査)と比較して偏っていないと判定できるか。

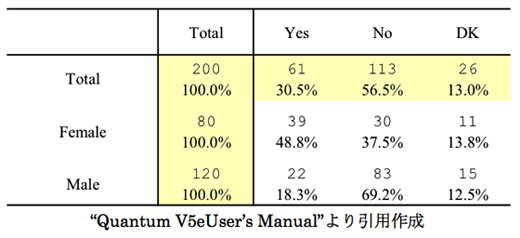
6.男女200人に、ある質問に対する諾否(はい・いいえ)を調査した。下表はクロス集計の結果である。母集団においても男女で意向率に差はない、といえるか。
7.農業試験場20か所でとうもろこしの収量を調べた。20区を「燐肥料を施した」10区と、「施さない」10区に無作為割当した。施肥により収量が増す、と判断できるか。

上記7例うち、1~4は正規分布、5と6はカイ2乗分布、7はt分布を利用して検定する。
<検定の手順>
まず検定が可能な調査結果である前提が満たされていなければいけない。定義された母集団からの無作為抽出(確率)標本を得ていることが、標本から母集団に向かって統計的検定による判断を下せる前提条件である。
検定の手順は、やや形式的であるが、以下のように確立されている。
1.帰無仮説と対立仮説を設定する
2.有意水準を設定する
3.検定統計量を計算する
4.P値を計算する
5.P値が有意水準より小さければ帰無仮説を棄却するか否かの判定を下す
これだけでは初心者には意味不明で、もっと説明が必要であろうが、そうするとさらに分かりにくくなる可能性があるので、先述の具体例1~4に適用してみる。これらの例は正規分布を使う検定である。
<例1>
この例は「母比率(p)の差の検定」として定式化できる。「同じ母集団からの~」という仮説は母比率が等しい(差がない)という帰無仮説として定式化できる。
1.帰無仮説と対立仮説の設定
帰無仮説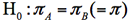
対立仮説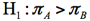
2.有意水準の設定
有意水準を0.05とする。
3.検定統計量(z0)の計算
未知のπの推定値として、2標本を合併した全体の標本比率p*を使う。
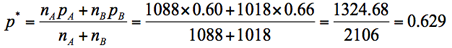
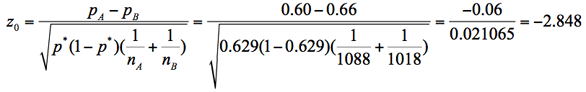
4.P値を計算する
検定統計量z0は正規分布に近似できるので、そこからP値は0.004と計算できる。
5.帰無仮説を判定する
P値(0.004) < 有意水準(0.05)であるので、帰無仮説を棄却する。すなわち、同じ母集団からの無作為抽出標本とは言いがたい。
ここで、帰無仮説を棄却したが、ただちに「異なる母集団からの標本調査を実施した」という結論を積極的に検証したわけではない。同じ母集団からの標本調査だが、標本誤差ではない誤差(非標本誤差)によって標本の内閣支持率に相違(統計的に有意な差)が観察されたという可能性を排除できない。
非標本誤差とは、統計理論から計算できる標本誤差ではないすべての誤差である。たとえば回収率が100%ではなく標本に偏りがあった場合、実査に質問方法の差異があった場合等の誤差の全体である。
<例2>
先の例1は両側検定だが、これは片側検定の例である。
1.帰無仮説と対立仮説の設定
帰無仮説
対立仮説
2.有意水準の設定
有意水準を0.05とする。
3.検定統計量(z0)の計算
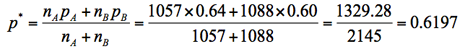
4.P値を計算する
検定統計量z0は正規分布に近似できるので、そこからP値は0.028と計算できる。
5.帰無仮説を判定する
P値(0.028) < 有意水準(0.05)であるので、帰無仮説を棄却する。すなわち、A紙とC紙は等しいとは言いがたく、C紙はA紙より「高い」といえる。ちなみに、有意水準を0.01に設定していたら、帰無仮説は棄却できなかった。
<例3>
これも片側検定である。
1.帰無仮説と対立仮説の設定
帰無仮説
対立仮説
2.有意水準の設定
有意水準を0.05とする。
3.検定統計量(z0)の計算
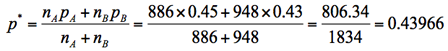
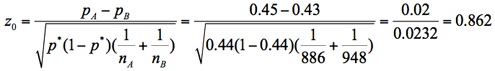
4.P値を計算する
検定統計量z0は正規分布に近似できるので、そこからP値は0.862と計算できる。
5.帰無仮説を判定する
P値(0.862) > 有意水準(0.05)であるので、帰無仮説を棄却できない。従って,1月から2月で支持率か低下したとはいえない。新聞紙面の記事においても2ポイント程度の変化を「低下した」と表現するのは,標本における観察事実ではあるけれど,母集団において「低下した」との表現は適切ではない。「横ばい」という程度の表現にすべきである。
<例4>
有権者の過半に支持されているという主張が否定されるのは、標本支持率がどれくらい低い場合か――という問題は、π=0.5という仮説検定であり、π<0.5の可能性に対してπ=0.5の当否を判断する片側検定(左側検定)となる。帰無仮説はπ>0.5であるが、このようなπは無数にあるため、通常はH0とH1の境界点π=0.5のもとでの検定統計量の分布を考える。
1.帰無仮説と対立仮説の設定 帰無仮説 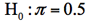 対立仮説
対立仮説 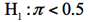
2.有意水準の設定
有意水準を0.05とする。
3.検定統計量(z0)の計算
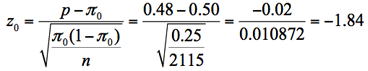
4.P値を計算する
検定統計量z0は正規分布に近似できるので、そこからP値は0.03と計算できる。
5.帰無仮説を判定する
P値(0.03)<有意水準(0.05)であることから帰無仮説は棄却されるので、母集団において過半の支持を得ているとはいえない。
<棄却域による判定>
これまでの説明では、P値を計算して有意水準と比較する手順を示したが、同値の手順として、検定統計量が棄却域に落ちたか否か、という判定方法もある。確率分布(正規分布など)を使う検定方法なので、幾何学的に分布図を想定することは自然である。統計学のテキストも棄却域を説明している。
実際に検定をする場合、現在では手計算することなく、コンピュータからP値が計算されるので、昔のテキストの巻末についている数値表を使うことも少なくなっている。
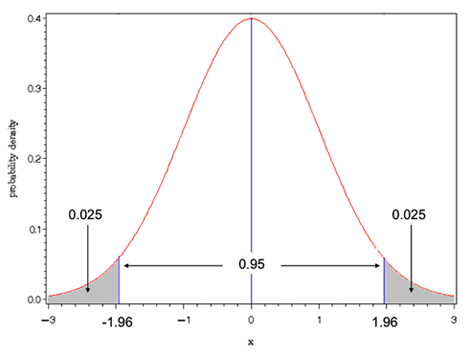
<例1>は両側検定である。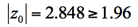 なので,有意水準5%で帰無仮説を棄却する。ここで1.96とは何かを下の標準正規分布(平均0、分散1に標準化した正規分布)をみて確認する。横軸(x座標)とベル型の曲線で囲まれた面積全体が1である。確率分布なので全体で確率1である。平均の0から右に1.96の点よりも大きい右側の面積(確率)が0.25であり、左へ-1.96よりも小さい左側の面積(確率)が0.25であり、両側の合計で0.05(有意水準5%)となり±1.96はそれを定める臨海値である。この灰色の部分を棄却域という。検定統計量がこの領域に落ちた場合に、帰無仮説を棄却するからである。これが、P値が0.05を下回ったということに対応する。
なので,有意水準5%で帰無仮説を棄却する。ここで1.96とは何かを下の標準正規分布(平均0、分散1に標準化した正規分布)をみて確認する。横軸(x座標)とベル型の曲線で囲まれた面積全体が1である。確率分布なので全体で確率1である。平均の0から右に1.96の点よりも大きい右側の面積(確率)が0.25であり、左へ-1.96よりも小さい左側の面積(確率)が0.25であり、両側の合計で0.05(有意水準5%)となり±1.96はそれを定める臨海値である。この灰色の部分を棄却域という。検定統計量がこの領域に落ちた場合に、帰無仮説を棄却するからである。これが、P値が0.05を下回ったということに対応する。
ちなみに、標準化しない棄却域、つまり元の単位で考えることもできる。
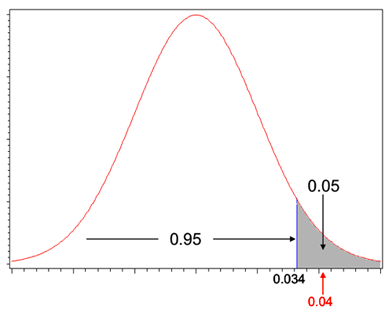
<例3>も片側検定だが、帰無仮説を棄却できなかった例である。検定統計量0.862は片側検定の棄却域(>1.64)に落ちないので、帰無仮説を棄却できない(1月から2月で支持率が「低下」したとはいえない)。標準化しない棄却域は
であり、支持率差0.02はこれよりも小さい差異である。1000人程度の世論調査の場合は、3ポイント程度は誤差ということである。
<○○検定とは>
●統計的検定
検定は一般名詞なので文脈から、漢字検定、秘書検定、英語検定などと区別する必要がある場合に「統計的検定」という。統計検定という資格試験があるが、統計的検定ではない。もちろん統計検定の試験問題に統計的検定は出題されている。
●有意性検定と仮説検定
統計学はひとつではない。20世紀に限定しても、フィッシャーの統計学、ネイマン-ピアソンの統計学、ベイズ統計学などがある。まずフィッシャーが有意性検定を提案した。ネイマンとピアソンは有意性検定を発展させて仮説検定を定式化した。有意性検定と仮説検定に大差はないとも見えるが、同時代のフィッシャーはネイマンとピアソンの仮説検定を激しく批判した。
しかし、ネイマンとピアソンの仮説検定は数学的にも完成しており、ネイマンが米国に移って統計学教育の世界的主流となった。現在、日本の大学教育で実施されているのはネイマン-ピアソン流の統計学である。
帰無仮説検定は仮説検定と同じである。検定するのは帰無仮説であって、対立仮説ではないことを明示している。統計的仮説検定ということもあるが、これも仮説検定と同じである。
一方、ベイズ統計学は著しく異なるともいえるが、21世紀はベイズ統計学が主流になるかもしれない。自然な解釈ができて実用的にも既に成功している。ネイマン-ピアソン流の仮説検定や区間推定も実績があり残るだろうが、一般に分かりにくく、多くの人々を誤解させているという背景もある。
<ややこしさ>
専門用語がいろいろ出てくるだけでなく、帰無仮説の設定(両側検定・片側検定)や、検定結果の解釈も背理法であるために、ややこしさがある。そもそも検定統計量の公式も、納得していないと丸暗記になる。
しかし納得するためには標本分布(確率変数と確率分布)を理解する必要がある。なぜなら検定は標本から母集団への帰納なので、母集団から標本への演繹、つまり標本統計量の確率分布が理論的根拠になっているためである。これらは数理統計学のテキストに解説されているが、理論は数学で書かれているため、数学が苦手な多数派の理解を阻んでいる。

