t検定(t-test)はt分布を利用する検定法の総称である。たとえば平均値、回帰係数など多くの場面でt検定は利用されている。
t分布を発見したのはゴセット(スチューデントの筆名で論文発表)であり、フィッシャーが数学的な定式化に協力した。
t分布は正規分布と関係が深く、自由度が大きくなればt分布は正規分布に漸近する。逆にいえばt分布を利用するのは小標本の場合である。
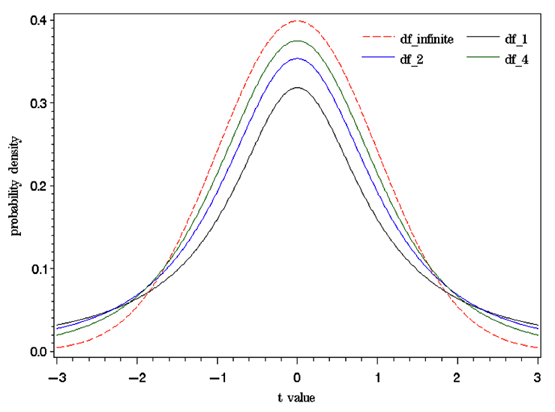
t分布と正規分布を比較した下図をみると、t分布は正規分布よりも裾を引いていることが分かる。
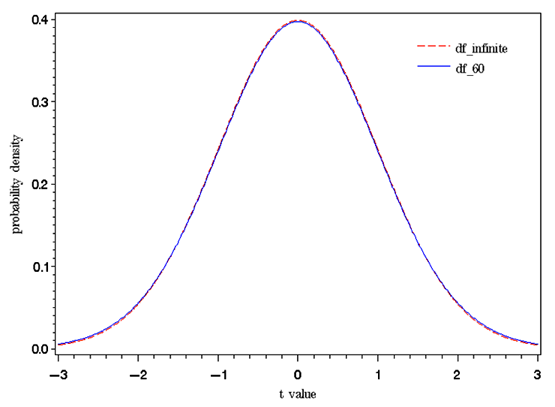
「大標本」というとビッグデータを想起するかもしれないが、たかだか60件以上になれば、正規分布の近似はかなりよい。下図は自由度60のt分布と正規分布であるが、ほぼ重なっている。つまり、t分布を使うt検定を適用するのは、標本サイズが5~6件しかないような場合である。マーケティング調査では数百人以上の調査を実施することが一般的なので、t検定を使わなければならない場面は少ない。
<t検定の例>
農業試験場20か所でとうもろこしの収量を調べた。20区を「燐肥料を施した」10区(A)と、「施さない」10区(B)に無作為割当した。施肥により収量が増す、と判断できるか。

これは「独立な・対応のない2標本の平均値の差の検定」である。平均値の場合には両群が等分散か不等分散か、大標本か小標本かで検定方式が異なる。ここでは母分散は未知の場合を考えるが,未知であれば等分散か否かも未知である。
分散未知だけれども等分散を仮定し、小標本の場合を扱うことになる。平均値の差がないという帰無仮説を有意水準5%で検定する(片側検定)。
1.帰無仮説と対立仮説の設定
帰無仮説 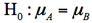
対立仮説 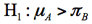
2.有意水準の設定
有意水準を0.05とする。
3.検定統計量(t)の計算
この検定統計量tは以下のように求められ,これが自由度nA+nB-2のt分布に従うことを利用して検定する。ここでSAとSBは各標本の偏差平方和である。
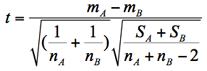
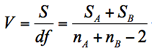
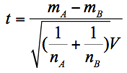
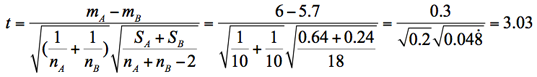
4.P値を計算する
t分布からP値は0.004と計算できる。
5.帰無仮説を判定する
P値は0.004で有意水準の0.05より小さいので有意であり、帰無仮説は棄却される。つまり施肥しても収量は増えない、という帰無仮説は棄却される。
<標本平均の統計的推測>
母平均に関する検定では、母集団分布が正規分布か非正規分布か,母分散(母標準偏差σ)が既知か未知か,標本サイズが大か小か――によって標本分布が異なる。それを整理したのが下図である。ここから分かるように、要するに大標本であれば正規分布に近似できるということである。t分布は小標本における標本分布であるが、母集団が正規分布であるという仮定が必要である。

<なぜt分布という名前がついているのか>
俗説はいくつか流布されているが、論文の中でtという記号が使われたためであり、それ以上の積極的な理由はない。メーリングリスト「fpr」で議論になったことがあり、東京大学の南風原朝和教授が、Eisenhart,C.(1979) On the transition from "Student's" z to "Student's" t.を抄訳して紹介している記事が参考になる。ゴセットとフィッシャーとのやりとりの過程でxやzが使われ、最終的にtという記号を使って定着したらしい。
http://mat.isc.chubu.ac.jp/fpr/fpr1997/0119.html

