判別分析は複数のグループのどこに判別されるかを決める場合に利用する統計モデルである。たとえば顧客満足度調査の結果から「満足」と「不満」のグループの特性を知りたい。あるいは新製品の「購入者」と「非購入者」を分けている原因は何か。または「自社顧客」と「他社顧客」の差異を明らかにしたい。
市場・消費者・顧客は単一ではなく、なんらかの属性で複数の同質なグループに分かれて構成されていることが多い。市場セグメンテーションはマーケティング分析の重要な手法であり、グループ別に戦略を立案することが有効である。
グループを識別する変数を分類変数と呼ぶ。基準変数、目的変数、従属変数に相当する。機械学習では教師データ(教師変数)という。グループは2群だけでなく3群以上であってもよい。
分析目的と応用分野は、
(1)予測
(2)要因説明
(3)知覚マップ
などである。
<予測>
予測を目的とする事例は、実はマーケティング分析では少ない。関連する事例としては、企業倒産を判別・予測するモデルがある。また日本経済新聞社がかつて企業評価モデルとして「CASMA」を発表していたが、これも優良企業の判別分析の応用であった。世論調査と関係のある選挙予測調査では、候補者の「当選」「落選」の判別予測、および当選確率の計算などに判別分析を利用する場合もある。
典型的な予測問題としては、診療結果から病気の種類(または病気か否か)を予測するシステム、あるいは発掘された人骨の測定結果から人種・性別・年代などを判別予測するシステムなどの利用例がある。
<要因説明>
顧客満足度調査などを実施すると、「満足」と「不満足」のグループを得る。マーケティング施策を考えうる際に、満足または不満足となっている要因を知り、そこから対策を決める。調査では価格や性能などの評価も測定しているし、利用・購入の際の重視点などもある。これらを説明変数として判別分析をすると、満足と不満足を分けている変数の影響力が算出できる。これが要因分析としての利用である。
<知覚マップ>
判別分析の結果として、判別座標(判別変量、判別軸ともいう)を得るので、最初の2~3個の軸を使って平面ないし空間に対象を布置することができる。これは主成分分析、コレスポンデンス分析の利用方法とまったく同じである。布置する観点が「何が満足度の差別化の要因となっているのか」という空間を構成するという違いである。空間の解釈も主成分分析と同様に、構造行列が計算されるので、元の変数との相関関係から判別変量を解釈する。
たとえばビールのブランドごとに消費者調査を実施して、味の評価を測定する。その結果として平面上にビールの競合マップを描くことができる。軸の解釈は構造行列から「コク」「キレ」などから味の差別化の観点が分かり、ブランドの位置関係の認知を可視化する。これがポジショニング分析への応用である。
<事例>
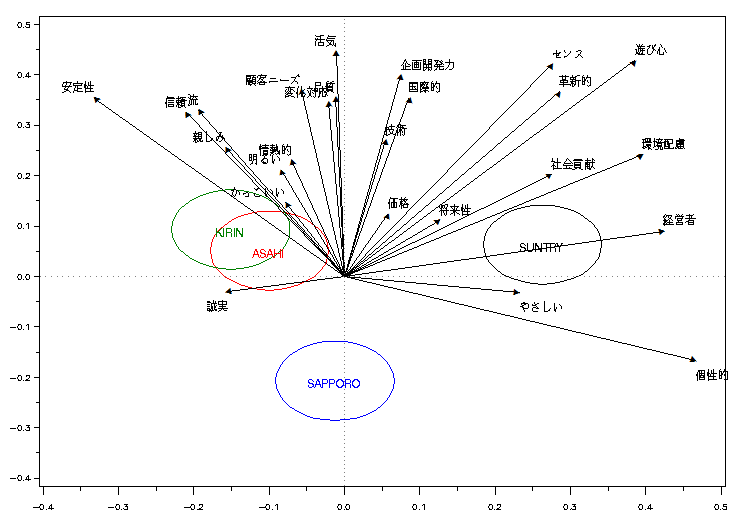
ブランド戦略サーベイのイメージ変数を使って、ビール4社を判別分析して知覚マップを作成した。原点から伸びているのは構造ベクトルというが、ブランドイメージの各変数である。縦軸・横軸(判別変量)と構造ベクトル(イメージ)との角度が共分散(相関)である。これを手掛かりに平面を解釈することができる。
右側は「やさしい」「経営者」「環境配慮」「個性的」などのイメージで、左側が「安定性」「誠実」である。サントリーが右、キリンとアサヒが左に位置して差別化されている。サッポロはその中間であり、横軸で判別されてはおらず、縦軸の下に位置する。他3社が上にある。上方は「活気」「品質」「変化への対応」などのイメージである。
このデータの判別分析の結果は、誤判別率が約7割と高い。そのため4社がよく分離されず、判別軸の解釈もやや難しい。とくにキリンとアサヒは2次元平面でよく区別されていない。
構造ベクトルは主成分分析、因子分析などでも得ることができる。因子負荷行列・ベクトルと同じものである。判別変量、因子得点、主成分得点などの合成変量と、もとの観測変数(ここではイメージ項目)との相関である。従って、主成分分析や因子分析でも知覚マップにベクトルを描くことができる。
このような知覚マップ、すなわち企業ブランド(行)とイメージ変数(列)を同時に描く手法をバイプロット(biplot)という。bi とは「ふたつの」という意味であり、バイセクシュアル、バイリンガル、バイアスロン、バイサイクル(二輪車)と同じ接頭辞である。ここでは変数(イメージ)と個体(企業ブランド)のふたつの同時プロットという意味である。
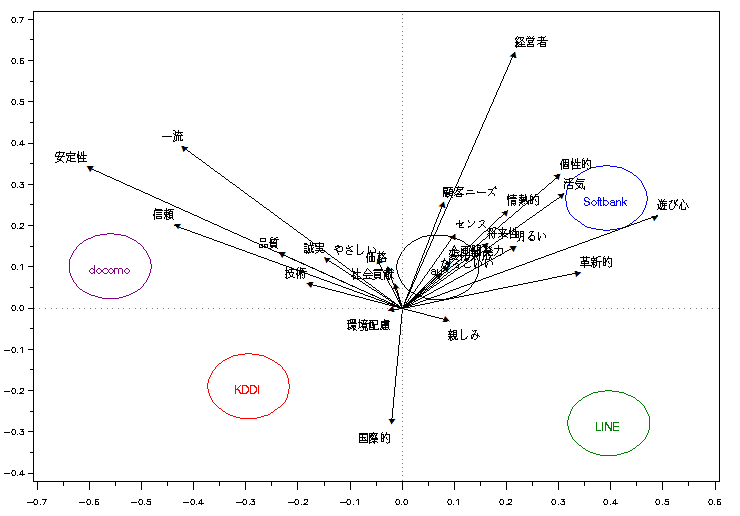
もうひとつの事例として携帯電話の5社を分析した。説明変数は同じである。この分析結果の誤判別率も約7割であったが、ビールよりはよく分離された知覚マップを描けている。
横軸で右にソフトバンクとLINE、左にドコモとKDDIが位置する。auはその中間である。右は「革新的」「遊び心」で、左は「安定性」「信頼」のイメージ空間であり、納得できるであろう。縦軸はやや解釈が難しく、下方に「国際的」というイメージが寄与しており、KDDIとLINEが位置する。auは原点付近にあり、この事例では中間的な布置となった。KDDIとauを含めて分析したが、ブランドイメージはやや異なるということが示された。
判別分析とよく似た分析方法としてクラスター分析がある。どちらも「分類」が基本的コンセプトであるが、判別分析は事前に分類が決まっているのに対し、クラスター分析は未定な状態からグループを形成する手法である。前者を「教師あり」、後者を「教師なし」のデータ(分析法)と呼ぶ習慣がある。「教師」とは一般に基準変数、外的基準などと呼ばれている。
<歴史>
判別分析はR. A. Fisher が多変量分散分析のアイデアをベースに分類問題に応用したもので、1936年に提案した。この論文で使われた3品種のあやめのデータは有名で、判別分析やクラスター分析の事例データとして使われることが多い。現在では特に正準判別分析と呼ばれる。
Fisher, R. A. (1936). "The Use of Multiple Measurements in Taxonomic Problems". Annals of Eugenics. 7 (2): 179–188.
日本では第二次世界大戦後、刑務所に収容される犯罪者が増加した際、釈放を早めたいが、再犯で戻る者と更生できる者を判別したうえで釈放したい、という問題意識から、林知己夫が判別手法を開発した。後年、数量化2類と呼ばれる手法だが、多変量分散分析と数理的には同値である。

