系統抽出は無作為抽出を実現するための実践的な手順である。無作為抽出は乱数を利用すれば簡単に実施できるが、枠母集団のリストが紙の名簿の場合はコンピュータだけでは抽出作業ができない場合があり、系統抽出はそのような場合にも便利である。住民基本台帳や選挙人名簿が典型的な事例で、現在はデジタルデータ化されているものの、役所で閲覧できる媒体は紙に印字された名簿なので、手作業で標本抽出する手順を準備しなければならない。
<系統抽出の手順>
1.抽出間隔(インターバル)を決める
2.無作為開始点(ランダム・スタート・ポイント)を決める
3.無作為開始点から抽出間隔ごとに、要素を所定数に達するまで抽出する
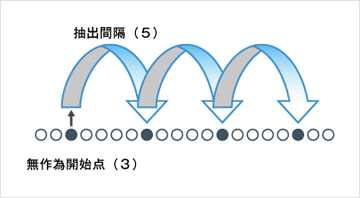
たとえば抽出間隔を5、無作為開始点を3とした場合、下図のように3、8(3+5)、13(8+5)番目~というように、数え上げながら順番に(系統的に)抽出する。●が抽出された要素である。抽出間隔が等しい(5)ので等間隔抽出という場合もあるが、後述するように系統抽出という用語が一般的に適切であろう。抽出間隔が5で固定されているにもかかわらず、これで無作為抽出といえるのだろうか。その根拠となる無作為性は、開始点を無作為に選ぶ、というところにある。
<手順に関する補足>
◉ 抽出間隔の決め方
抽出間隔は、理論的にだけいえば、どのように決めても良い。しかし現実的には調査プロジェクトに適した決め方を考案しなければいけない。
[極端な決め方]
抽出間隔を1としても良い。それは「開始点が無作為なら母集団の要素の包含確率は等しい」という意味においてのみ良いだけであり、現実問題としては良くない不適切な場合が多い。住民基本台帳から個人を抽出する場合を考えれば、容易に不適切性が理解できる。同じ家族の人員が選ばれてしまうが、このような標本が適切であるような調査は、ほぼ無い。
[全体に行きわたるように決める]
母集団の全体から一様に抽出したいという動機からは、抽出間隔をd = N / nで決めることが多い。Nは母集団サイズ、nは標本サイズ、dは抽出間隔である。この決め方の欠点はN / nが一般に整除できないためnに過不足が生じることである。不足回避のために切捨てることが多いが、そうすると末端の要素が抽出されない。N = 10、n = 3の場合、抽出間隔は10/3の切捨で3となる。無作為開始点を dより小さい整数乱数とすると、可能な候補は1、2、3だけになり、10番目の要素は決して抽出されない。つまり抽出確率0となる。
母集団の要素が下図のように円環状に並んでいると考えれば、無作為開始点を区間(1、N )の一様乱数(整数)を1つ発生させて決めることで、この問題は解決する。抽出間隔d はN / nに近い整数とすればよい。ただし名簿を円環状に扱える、つまり名簿の末端に達したら先頭に戻ることができる状況が必要である。

過不足問題を回避するために、抽出間隔 d = N / n を整数にまるめず、そのまま使う方法もある。必ずしも等間隔抽出とならないが、必ず正確にn個を抽出できる。この意味で系統抽出のことを等間隔抽出とよぶのは都合が悪い。英語のsystematic sampling を直訳した系統抽出がよい。この手順は母集団の要素がデジタルデータ化されている場合に適しているが、手作業の場合には不等間隔になることで、人間的作業に間違いを引き起こす危険性に注意が必要となる。具体的なアルゴリズムは以下のようになる。小数点以下も含めて加算することで過不足を生じさせないようにする。
〈1〉d = N / n とする(整数化しない)
〈2〉区間( 0, 1 )の一様乱数 u を1つ生成する
〈3〉ik = ceil( ud + ( k1 )d ) としてik 番目の要素を抽出する( k = 1, 2, ;, n )
ceil( a ) は引数 a 以上( a と同じか、a より大きい)の最小整数を返す関数である。
[実査の都合で決める]
調査員による訪問調査では、抽出作業と実査の都合でdを11とか21とかに、主観的判断で決めることが多い。全国規模の訪問調査で数千人規模の調査の場合は、しばしば多段抽出が採用されるために、数百の調査地点が設計される。
標本抽出作業は数百もの地点について、それぞれの地点が属す役所に出向いて名簿を閲覧するのだが、地点ごとに異なる抽出間隔にすると管理が複雑になるほか、規模の大きな地点では、大きな数を数え上げながら、何十ページも名簿をめくる作業になり、誤りを犯す危険性が高まる。また実査を担当する調査員にとって、ある地点では歩いて次の調査対象者宅に容易に行けるが、別の地点の調査員は電車で次の対象者宅まで移動することになる。これも管理上は避けたい。
11とか21という主観的決定は、抽出作業においても適切で統一的な作業を実現し、実査では数軒おきに歩いて訪問できる数字として考案した結果である。全国規模の調査であれば、住居が密集している地点は21とし、過疎地点は11とするような使い分けをしてもよい。
奇数にしている理由は周期性を回避するためであるが、やや;気休め;の側面がある。2人世帯が多いことは事実ではあるが。
◉ 無作為開始点の決め方
以下の二通りの決め方がある。
[抽出間隔以下の乱数]
区間(1、d)の一様乱数(整数)とする。この場合、上述するように整数化の際に切捨処理をすると、末端の要素の抽出確率が0になってしまう欠点を回避する必要がある。
[母集団サイズ以下の乱数]
区間(1、N)の一様乱数(整数)とする。標本抽出枠が円環状配列とみなして、末端に到達したら先頭に戻ることができれば、この決め方が汎用性を持つ。
<特徴と注意事項>
系統抽出の特徴、およびそれに伴う注意事項などをまとめる。
[不適格要素の扱い]
標本抽出枠に不適格要素を含む場合がある。たとえば住民基本台帳を枠母集団としながら、目標母集団は成人である場合、系統抽出で未成年者があたることがある。そのような場合は、不適格要素を捨てて、次の要素まで数え上げて進めばよい。生年月日を確認しながら不適格要素を除外しつつ数え上げると、間違えやすい。
[配列と周期性]
系統抽出する場合の枠母集団の要素は無作為に配列されている必要がある。少なくとも周期性があり、その周期が抽出間隔と比例関係になっていると良くない。系統抽出には統計理論上の欠点もあるが、実質的に無作為抽出を前提として推測をしているからである。しかし、現実は理論と常に乖離しているので、実態をよく確認したうえで手順を考案することになる。
周期性の例は「枠母集団の名簿が男女交互に並んでいて抽出間隔が偶数」というような場合である。下図左は抽出間隔4の系統抽出の例で、●が抽出された要素である。母集団の男性比率がπ=50%であっても、標本の男性比率はp=100%かp=0%のいずれかになってしまう。男性比率の分散は0になってしまい、統計的な推定ができない。数理的には、n=1の標本調査と同じ精度になる。下図の例で偶数が男性だとすると、左図の系統抽出の標本男性比率は100%である。右図の単純無作為抽出の標本男性比率は50%で、母比率と一致している。一致したのは偶然だが、少なくともn=20の標本で男性比率が100%か0%になるような結果は、ほぼ生じないであろう。

[層化効果]
無作為抽出の場合、母集団に関する知識を利用して層化抽出をすると、単純無作為抽出よりも精度が高まる。母集団の要素を、層化しながら無作為に並び替えたうえで、系統抽出すると、母集団の全体から一様に抽出しながら、結果として層化と同等の効果を期待できる。
[ゾーン抽出]
周期性の問題を回避する工夫として、ゾーン抽出がある。これは母集団において要素をいくつかのゾーンにグループ化しておき、まず要素が系統抽出されると、その要素が所属するゾーンの中で、再度、要素を単純無作為抽出する方法である。
ゾーンは単純無作為抽出できる程度の大きさであるか、デジタルデータ化されている必要がある。たとえば電話番号をRDDサンプリングする場合、まず電話番号を系統抽出し、次に抽出された電話番号の属す局番の中で、再度、1万個の電話番号から1個の番号を単純無作為抽出するという方法が考えられる。局番がゾーンである。

