多数の調査項目があり、それらが互いに相関を持っている場合[1]、その重なり合っている情報を数理的に合成し、より少ない新しい変数によって、できるだけ多くの情報を保存しながら全体を簡潔に説明することができる。その代表的なデータ分析法として主成分分析がある[2]。合成された変数を主成分(principal component)という。元の変数群が持っている情報から主要な成分を合成する、という意味である。
日経リサーチの「ブランド戦略サーベイ」では、企業ブランドに対するイメージとして25項目を調査している。企業に対する印象を質問しており、相関係数を計算してみると、下表のように互いに相関関係があることが分かる。このデータを主成分分析すると、相関関係を考慮した新しい合成変数(主成分)を導くことができる。

主成分分析はマーケティング調査におけるポジショニング分析のほか、総合指標を作成する場面で利用されることが多い。日本経済新聞に掲載されている企業評価ランキングでは、調査データをもとに主成分分析を適用した結果が使われている。1997年に始まった環境経営度調査の企業ランキングでは主成分分析が利用された。また品質経営度調査でも、主成分分析によるスコアで企業ランキングが発表されている。
<企業ブランドイメージの総合指標>
総合指標ランキングを作成する場合は、第1主成分を利用する。企業ブランドイメージの第1主成分得点の大きい順にランキングすると、下表のようになる。
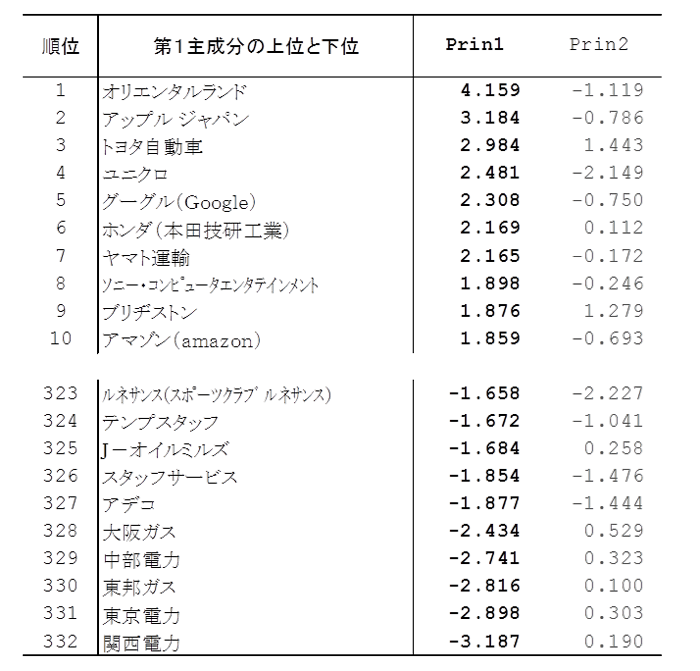
トップはオリエンタルランド。上位にはインターネット時代を象徴するアップル、グーグル、アマゾンのほか、産業界を代表する自動車業からトヨタ、ホンダ、ブリヂストン。また生活に密着している商品・サービスを提供して成功しているユニクロ、ソニー・コンピュータエンタテインメントが上位10社である。
このランキングはイメージ25項目を総合的に合成した得点に基づくもので、人々の心の中に蓄積されているイメージの多さ・豊かさを示していると解釈できる。
最下位には電力・ガスなどのインフラ企業が並んでいる。有名で身近ではあるものの、企業による差別化は知覚されず、特色のあるイメージが形成されているわけではない。いわば水や空気のような存在形態となっているが、競争が自由化されると変化する可能性がある。
<企業ブランドイメージのポジショニング分析>
主成分分析の結果からは、第1主成分だけしか得られないわけではない。後述するように第2主成分以下も得られる。下表は第2主成分得点の上位と下位の企業だが、第2主成分は第1主成分とは性質が異なる。数理的には無相関(直交する)という性質を持つ。意味的には型(タイプ)を反映した指標である。
三菱重工業とドン・キホーテは企業イメージの型としては正反対に認識されている。イメージの量的側面とは無関係である。企業ブランド名を眺めると、重厚長大ではなく軽薄短小、あるいは新と旧。格式高く真面目でカタイか、庶民的で楽しく柔らかいか――。そのようなブランドイメージの型の対比を第2主成分は示している。その両極として製造業とサービス業の業界対比にもなっている。あるいは時間概念としての伝統と現在との対照にもなっている。それを体現している代表格が、三菱重工業とドン・キホーテという分析結果になった。

第1主成分と第2主成分を座標として使えば、下図のようなイメージマップを描いて、企業のポジションを把握することができる。イメージマップは知覚マップということもある。地理的・物理的な地図ではなく、調査によって人々の意識を調べたデータから、人々の知覚した企業イメージの地図、つまり知覚された各企業の位置関係を可視化したマップである。
<主成分分析による知覚マップ>
主成分得点はすべての企業で算出されるが、下図では見やすいように配慮する目的で、主成分得点の上位と下位の企業に絞って2次元の散布図を描いている。実際には332社が布置されている。
横軸の第1主成分は量的な大きさ、縦軸の第2主成分はイメージの型という対比となっている。
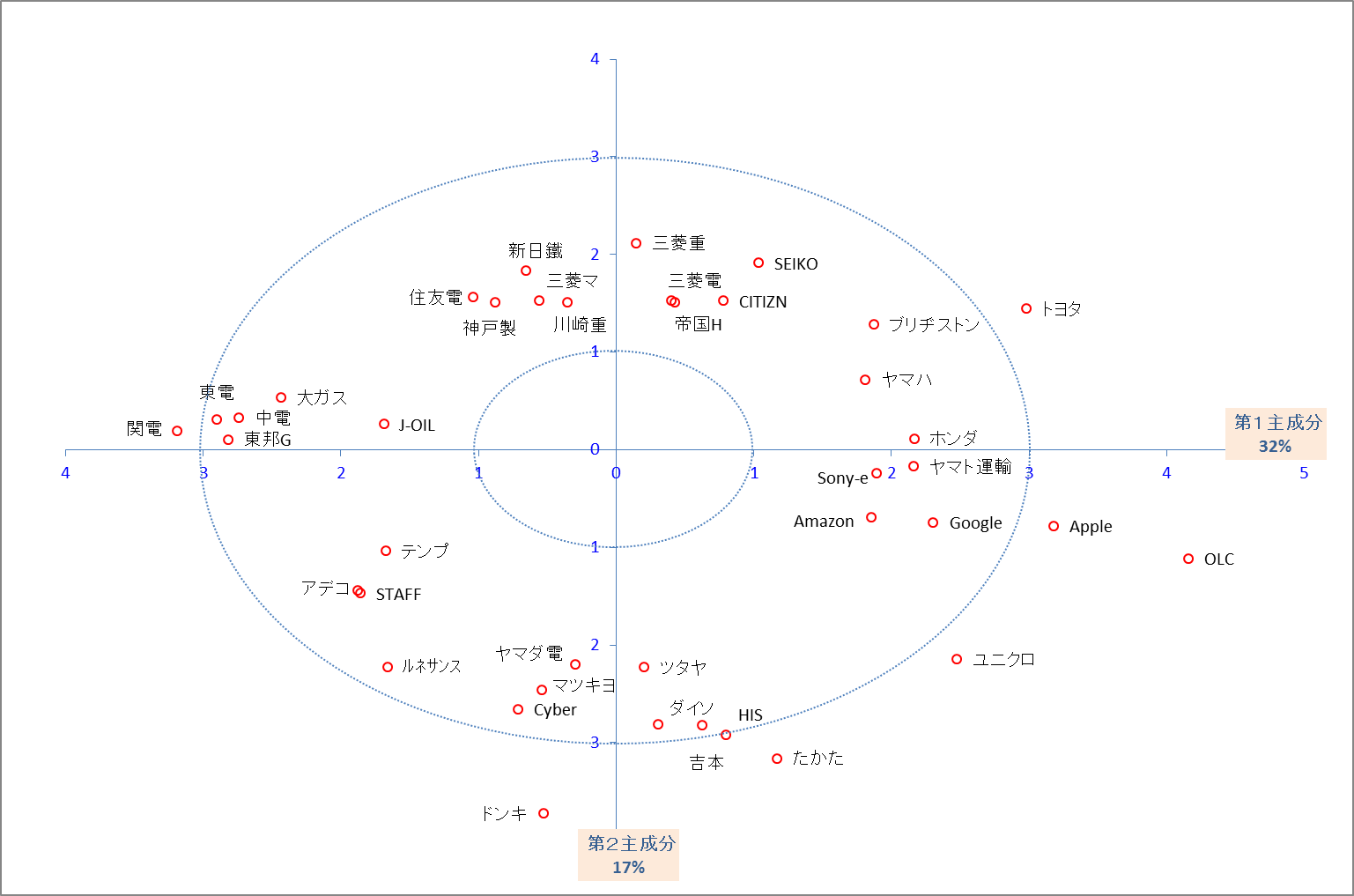
知覚マップは空間的な意味を解釈することができるので、自社と競合他社との位置関係と同時に、どのように知覚されているかが明らかになる。それが企業のブランド戦略と一致していなければ、リ・ポジショニング戦略を立案するために利用できる。
自社に近い位置にある企業が競合関係にあって、イメージが似ている場合、芸人にたとえれば「芸風がカブ」っているのかも知れない。必要なら差別化を打ち出すべきコミュニケーション戦略を考えることもあるし、その位置が「良い場所」ならば、3位以下を引き離して上位を2社でその場所を占有する戦略を採用することもある。
知覚マップはこのような議論の実証的根拠としてマーケティング調査で利用されるが、知覚マップを作成する方法は主成分分析だけではなく、因子分析や判別分析や多次元尺度法も使われる。それぞれの分析手法の特徴を生かして、どのような知覚マップでレポートすべきかを判断する。
<主成分分析の特徴>
主成分分析は下のように相関行列Rの固有値問題を解いているだけであるが、
その結果として得られる主成分とは、どのような特徴を持っているのかを整理すると、おおむね以下のようになる。
- 第1主成分は元の変数による、あらゆる線形合成のうち、最大の分散を持つ。
- 第2主成分は、第1主成分と無相関という制約のもとで、最大の分散を持つ。
- 第3主成分以下も同様に、その前の成分と無相関という条件のもとで、最大の分散を持つように、次々に線形合成をして、元の変数と同じ個数だけの主成分を得る。すなわち、元の変数の線形合成として、分散の大きい順に変換した直交成分を、元の変数と同じ個数だけ得るデータ変換手法である。
- 主成分の分散の合計は、元の変数の分散合計と等しい。つまり主成分に変換してもデータの持つ情報の総量が変化するわけではない。相関行列の主成分分析であれば、変数が標準化されているので、25変数であれば分散合計は25となる。主成分の分散合計も25である。主成分分析で情報が増加するのではなく、情報を傾斜させているのである。
- 分散の大きい、最初の数個の主成分で、全体の主要な情報を縮約することができれば効率的である。最後の方の分散の小さい主成分は誤差とみなす。分散が大きいということは、情報が多いということである。
- 元の変数の相関行列の要素がすべて正の場合、第1固有ベクトルの要素はすべて正となり「大きさの成分」という。第2固有ベクトルは正負混合し「形の成分」という。たとえば、体重と身長の2変数を主成分分析すると、第1主成分は「体格」、第2主成分は「体型」というべき成分に変換される。
- 下図がその例で、下左図のように身長と体重は正の相関がある。2変数の主成分分析では、変換を目視することができる。相関楕円の長軸方向が第1主成分、短軸方向が第2主成分となる。下右図のように2変数の場合は45度に座標変換するだけであり、点間距離は変化しない様子を示している。直交化と分散の傾斜(再配分)で「見方」を変えただけで、データ全体は変化しない。多変量の場合もこの拡張である。

<固有ベクトル=重みベクトル>
主成分の分散は、線形代数の用語では固有値という。主成分は元の変数の線形合成であったが、その重み係数のベクトルを固有ベクトルという。企業ブランドイメージの25変数の固有ベクトルは下表である。最初の5成分の固有ベクトルだけを示している。
第1固有ベクトルの要素の符号はすべて正である。相関行列には負の相関も含まれていたが0に近いため、25変数はおおむね同じ方向性を持っていたからである。一方、第2固有ベクトル以下の要素は正負混合している。

主成分は元の変数の線形合成であったが、固有ベクトルが元の変数にかける重み係数を要素とするベクトルである。線形合成のための係数をまとめたベクトルを一般に重みベクトルという。第1主成分の線形合成は下式となる。
f1=0.160z1+0.137z2+⋯+0.169z25
第1固有ベクトルはあらゆる係数のうちで最大の分散を与えるが、制約条件としてノルムを1とする。ノルムとはベクトルの長さで、各要素の平方和である。上表で固有ベクトルのノルムが1となっていることが確認できる。
<固有値=分散>
行列の固有値問題を解くということは、行列を固有値と固有ベクトルに分解することであるが、主成分分析において相関行列の固有値は主成分の分散であり、固有ベクトルは主成分得点を算出するための重みであった。
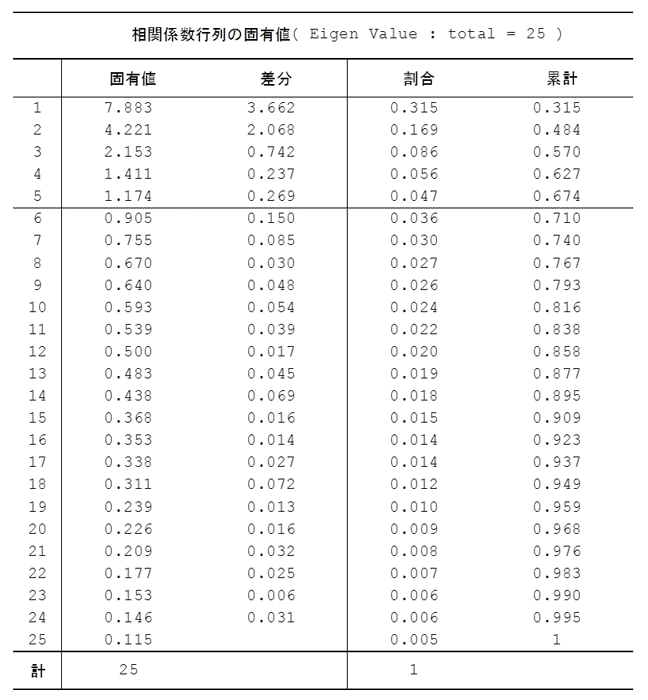
下表は企業ブランドイメージ25変数の固有値である。1より大きい固有値は5個であり、25成分の固有値の合計が25であることが確認できる。第5主成分までの累積寄与率は67%である。元の5変数の寄与率20%(=5/25)に比較すると、最初の5成分で7割近い情報を集約できたのである。
<主成分の意味を解釈する>
合成された主成分は、元の変数のように「親しみやすい」などの具体的な意味が表示されていない。そこで主成分は元の変数との関係を手掛かりとして「解釈」することになる。当然のことながら主成分の意味は、元の変数の意味表示よりも抽象的になる。
主成分の解釈は固有ベクトルでも可能だが、もっと分かりやすいのは、主成分と元の変数との相関係数を要素とする構造ベクトル(下図)である。
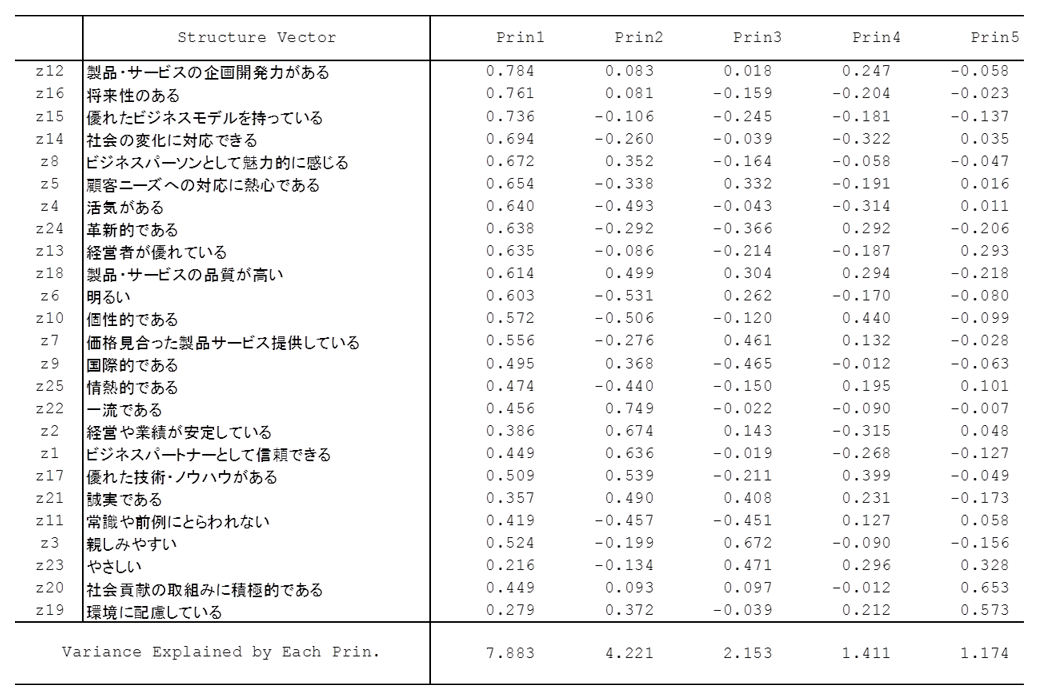
第1主成分の構造ベクトルの符号はすべて正なので、イメージの総合指標だと解釈できる。第2主成分は正負混合しているが、それぞれの主な変数を列挙する。
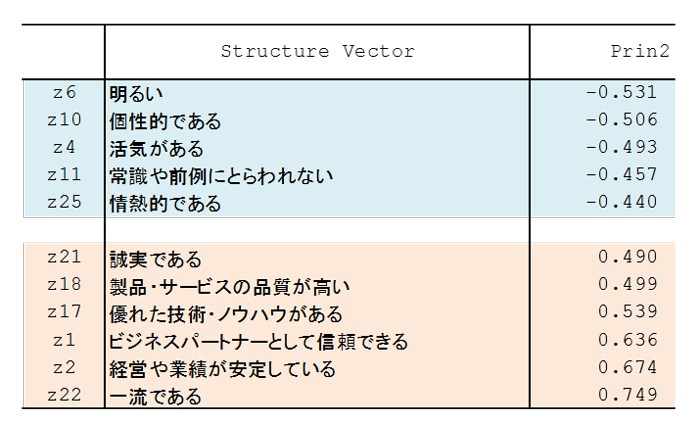
第2主成分は負の方向に、「明るく個性的で、活気と情熱で常識・前例にとらわれない」イメージ、正の方向に「一流・安定・信頼・品質・誠実で優れた」イメージで、ちょうど正反対のタイプ、また企業ブランドの型の相違になっている。これを手掛かりに第2主成分を解釈して、適当な抽象的名称をつけてもよい。「伝統-革新」の軸であるとか、「過去-未来」とか、「静的-動的」とか、である。そこに具体的な企業ブランドが対応しており、それが「三菱←→ドンキ」に象徴されている。
構造ベクトルは一般に、合成変数と元の変数との相関係数を要素とするベクトルである。その平方和が分散(固有値)に一致する。上表の第1構造ベクトルの要素の平方和である7.883は、まさに第1固有値の値である。
構造ベクトルaと重みベクトルwとの間には、固有値λを介して、以下の比例関係がある。
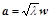
<主成分をいくつ利用するか>
絶対的な基準はない。寄与率80%以上という基準には一般的な根拠はない。結局、解釈可能な個数にすればよい。
解釈可能という観点からは「固有値の大きさが1より大きい個数」という基準(固有値基準、あるいはカイザー基準という)が目安になる。相関行列を主成分分析する場合、固有値が1より大きいということは、元の変数1個分以上の情報を持つ成分ということになるからである。しかし、固有値が1程度の場合は、特定の変数にのみ関係する成分となる場合もあって、複数の変数を「合成」した成分とならず、その結果として解釈が難しいときもある。その意味では、因子分析のほうが解釈しやすいので、マーケティング調査では主成分分析よりも因子分析が利用されることが多い。
データが持つ本質的な次元の数という観点からは、スクリー(scree)[3]基準で決める方法が簡単で使いやすい。スクリープロットは下図のように第1固有値から(つまり大きい)順に、折線グラフを描くだけである。
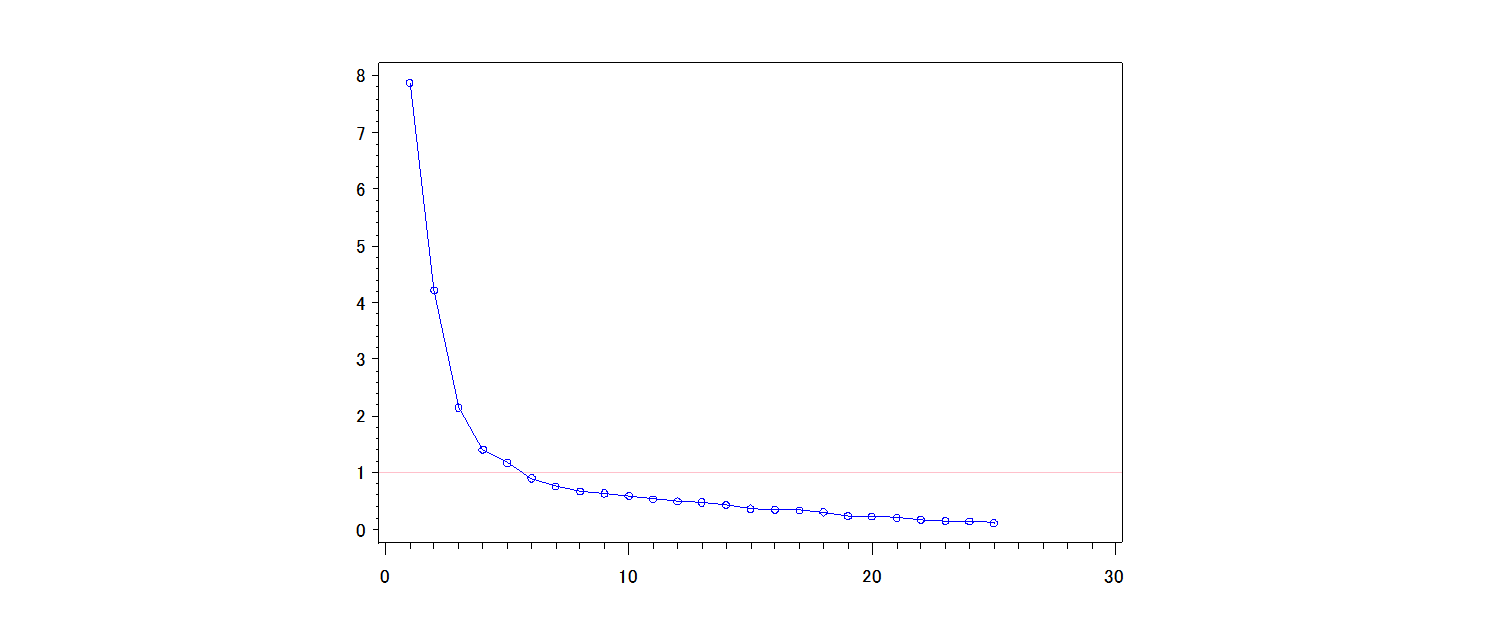
仮に、25変数の本質的な次元数が5であるとすれば、第6固有値以降は平行になる。「本質的」という意味は25変数の行列のランクが5である、というような状況である。実際のデータでは、正確に次元が定まってはいないが、ゆるやかに平行に近くなるところがあれば、その直前までを採用すべき成分の個数とする。これがスクリー基準である。
<相関行列か共分散行列か>
変数の単位がすべて同じ場合は、共分散行列を分析してもよいが、単位が異なる変数が混在している場合は相関行列を分析する。相関行列ということは変数が基準化されているということなので、単位の相違による影響は消えているからである。単位が同じ場合でも、分散が大きく異なる場合は、分散の大きい変数だけに影響を受ける主成分が構成される。もしも特定の変数が重要であるという前提がなく、同様の重要性で分析したい場合は、単位が同じ場合でも相関行列を分析するほうが、無難な結果を得られる。
<固有値とは何か>
線形代数における固有値問題は高校数学では学ばない。大学においても理科系では1年生で学ぶが、文科系では数学を使う分野(計量経済学など)を除いて学ぶ機会がない。そのため主成分分析を固有値問題として説明されると、理解が困難な人が多い。しかし、主成分分析を理解し、データ分析で利用するためには、必ずしも固有値問題を数学的に理解していなくてもよい。また、固有値問題を知っているからといって主成分分析を使って、実際のデータ解析を上手に実施できるとは限らない。むしろ主成分の性質を理解していることがデータ解析の成功にとって重要なことである。

